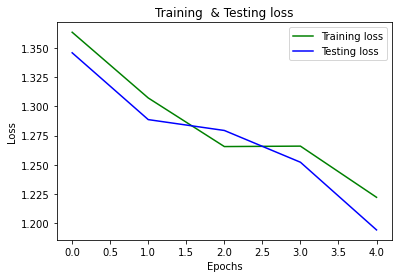
Hi there I am training a model for the function train and test given here, finally called the main function. I need to see the training and testing graphs as per the epochs for observing the model performance. Can someone extend the code here?
import torch
from torch.utils.data import DataLoader as DL
from torch import nn, optim
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from torch.utils.data import DataLoader
from SpeechDataGenerator import SpeechDataGenerator
from models.Emo_Raw_TDNN_StatPool import Emo_Raw_TDNN
import fit_predict as fp
from utils import utils_wav
from sklearn.metrics import confusion_matrix
from utils.utils_wav import speech_collate
torch.manual_seed(0)
torch.cuda.manual_seed(0)
def breaker():
print("\n" + 50*"-" + "\n")
tr_info_file = "meta/training.txt"
ts_info_file = "meta/testing.txt"
tr_batch_size = 16
ts_batch_size = 16
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
epochs = 100
if __name__ == "__main__":
tr_audio_links = [line.rstrip('\n').split(' ')[0] for line in open(tr_info_file)]
ts_audio_links = [line.rstrip('\n').split(' ')[0] for line in open(ts_info_file)]
tr_raw = []
for i in range(len(tr_audio_links)):
tr_raw.append(utils_wav.load_data_wav(tr_audio_links[i]))
tr_raw = np.array(tr_raw)
ts_raw = []
for i in range(len(ts_audio_links)):
ts_raw.append(utils_wav.load_data_wav(ts_audio_links[i]))
ts_raw = np.array(ts_raw)
dataset_train = SpeechDataGenerator(manifest='meta/training.txt',mode='train')
dataloader_train = DataLoader(dataset_train, batch_size=tr_batch_size ,shuffle=True,collate_fn=speech_collate)
dataset_test = SpeechDataGenerator(manifest='meta/testing.txt',mode='test')
dataloader_test = DataLoader(dataset_test, batch_size=ts_batch_size ,shuffle=False,collate_fn=speech_collate)
torch.manual_seed(0)
model = TDNN(1, 4).to(device)
optimizer = optim.Adam(model.parameters(), lr=0.0001, weight_decay=0.0, betas=(0.9, 0.98), eps=1e-9)
loss_fun = nn.CrossEntropyLoss()
from time import time
import os
start_time=time()
def train(dataloader_train,epoch):
train_loss_list=[]
full_preds=[]
full_gts=[]
model.train()
est=time()
for i_batch, sample_batched in enumerate(dataloader_train):
features = torch.from_numpy(np.asarray([torch_tensor.numpy() for torch_tensor in sample_batched[0]])).float()
labels = torch.from_numpy(np.asarray([torch_tensor[0].numpy() for torch_tensor in sample_batched[1]])).long()
features, labels = features.to(device),labels.to(device)
features.requires_grad = True
optimizer.zero_grad()
pred_logits = model(features)
#### CE loss
loss = loss_fun(pred_logits,labels)
loss.backward()
optimizer.step()
train_loss_list.append(loss.item())
#train_acc_list.append(accuracy)
if i_batch%100==0:
print('Loss {} after {} iteration'.format(np.mean(np.asarray(train_loss_list)),i_batch))
predictions = np.argmax(pred_logits.detach().cpu().numpy(),axis=1)
for pred in predictions:
full_preds.append(pred)
for lab in labels.detach().cpu().numpy():
full_gts.append(lab)
mean_acc = accuracy_score(full_gts,full_preds)
mean_loss = np.mean(np.asarray(train_loss_list))
print('Total training loss {} and training Accuracy {} after {} epochs'.format(mean_loss,mean_acc,epoch))
print('Time Taken for Epoch: {:.2f} minutes'.format((time() - est)/60))
def test(dataloader_test,epoch):
model.eval()
with torch.no_grad():
val_loss_list=[]
full_preds=[]
full_gts=[]
for i_batch, sample_batched in enumerate(dataloader_test):
features = torch.from_numpy(np.asarray([torch_tensor.numpy() for torch_tensor in sample_batched[0]])).float()
labels = torch.from_numpy(np.asarray([torch_tensor[0].numpy() for torch_tensor in sample_batched[1]])).long()
features, labels = features.to(device),labels.to(device)
pred_logits = model(features)
#### CE loss
loss = loss_fun(pred_logits,labels)
val_loss_list.append(loss.item())
#train_acc_list.append(accuracy)
predictions = np.argmax(pred_logits.detach().cpu().numpy(),axis=1)
for pred in predictions:
full_preds.append(pred)
for lab in labels.detach().cpu().numpy():
full_gts.append(lab)
mean_acc = accuracy_score(full_gts,full_preds)
mean_loss = np.mean(np.asarray(val_loss_list))
print('Total Test loss {} and Test accuracy {} after {} epochs'.format(mean_loss,mean_acc,epoch))
model_save_path = os.path.join('save_model', 'best_check_point_'+str(epoch)+'_'+str(mean_acc))
state_dict = {'model': model.state_dict(),'optimizer': optimizer.state_dict(),'epoch': epoch}
torch.save(state_dict, model_save_path)
if __name__ == '__main__':
for epoch in range(epochs):
train(dataloader_train,epoch)
test(dataloader_test,epoch)
'''
please guide
I know the first need is to save the model accuracies and loss, for this model need to save But how to plot this using skelearn or any other way that I need to know here.
Thanks