Hi all,
This may be not a difficult question, but it has bothered me a few days! Really need some help.
I have trained a model with following structure:
RNNModel_GRU(
(embed): Embedding(6, 1, padding_idx=1)
(gru): GRU(1, 64, bidirectional=True)
(linear1): Linear(in_features=128, out_features=32, bias=True)
(linear2): Linear(in_features=32, out_features=1, bias=True)
**(b_n): BatchNorm1d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)**
(dropout): Dropout(p=0.2)
(relu): ReLU()
)
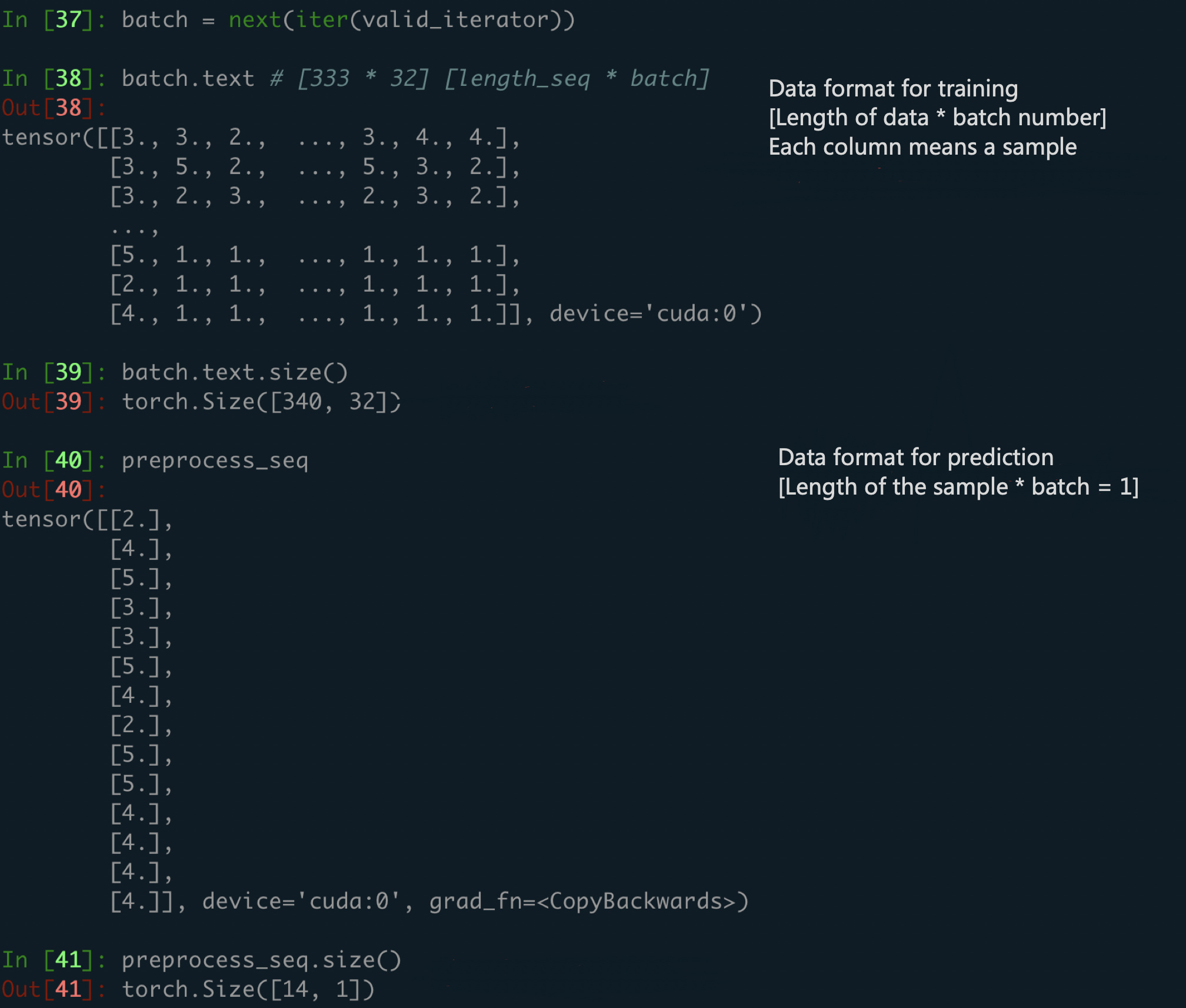
Now I’m going to load this model and predict new examples, since I’ve trained the model by feeding 32 data per batch, when I try a single new data to the model, an error occurs:
In [259]: scores = model(preprocess_seq)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-259-3ccf22219850> in <module>()
----> 1 scores = model(preprocess_seq)
/picb/rnomics3/wangmr/INSTALL/miniconda3/envs/GPU/lib/python2.7/site-packages/torch/nn/modules/module.pyc in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
<ipython-input-219-9bb382769aa2> in forward(self, text)
28 linear1 = self.relu(linear1)
29 linear1 = self.dropout(linear1) # [32 * 32]
---> 30 **b_n = self.b_n(linear1) # 32 * 32**
31 linear2 = self.linear2(b_n)
32
/picb/rnomics3/wangmr/INSTALL/miniconda3/envs/GPU/lib/python2.7/site-packages/torch/nn/modules/module.pyc in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
/picb/rnomics3/wangmr/INSTALL/miniconda3/envs/GPU/lib/python2.7/site-packages/torch/nn/modules/batchnorm.pyc in forward(self, input)
58 @weak_script_method
59 def forward(self, input):
---> 60 self._check_input_dim(input)
61
62 exponential_average_factor = 0.0
/picb/rnomics3/wangmr/INSTALL/miniconda3/envs/GPU/lib/python2.7/site-packages/torch/nn/modules/batchnorm.pyc in _check_input_dim(self, input)
167 if input.dim() != 2 and input.dim() != 3:
168 raise ValueError('expected 2D or 3D input (got {}D input)'
--> 169 .format(input.dim()))
170
171
**ValueError: expected 2D or 3D input (got 1D input)**
The debug info shows maybe some problems on input data size.
Indeed, the size of batch.text is [Length32][32 = Batch Size] during training, but the size of the single new data is [Length1]. I’ve tried to repeat the single data 32 times to match the batch size, but this really looks silly! How can I break the constrains of batch size, in an elegant way?