I am trying to minimise the mse loss with constrain loss but constrain was increasing instead of decreasing.then i tried to only minimise constrain then it throw following error.
class Edge_Detector(nn.Module):
def __init__(self,kernel_size,padding):
torch.manual_seed(1)
super(Edge_Detector,self).__init__()
self.sobelx=nn.Conv2d(1,1,kernel_size=kernel_size,padding=padding,bias=False)
self.relu=nn.ReLU()
self.sobely=nn.Conv2d(1,1,kernel_size=kernel_size,padding=padding,bias=False)
def forward(self,x):
x1=self.sobelx(x)
x2=self.sobely(x)
x=self.relu(x1+x2)
return x
def loss(self,x,y):
x=x.view(x.size(0),-1)
y=y.view(y.size(0),-1).float()
sobelx=self.sobelx.weight.data.squeeze().squeeze()
sobely=self.sobely.weight.data.squeeze().squeeze()
loss_mse=nn.MSELoss()(x,y)
loss_constrain=torch.matmul(sobelx,sobely.transpose(0,1)).trace()
#print('mse_loss : ',loss_mse)
#print('constrain_loss : ',loss_constrain)
#total_loss=loss_mse+loss_constrain
return loss_constrain
#Error Message:
RuntimeError Traceback (most recent call last)
<ipython-input-67-28b5b5719682> in <module>()
----> 1 learn.fit_one_cycle(15, 5e-2) #training for 4 epochs with lr=1e-3
13 frames
/usr/local/lib/python3.6/dist-packages/torch/autograd/__init__.py in backward(tensors, grad_tensors, retain_graph, create_graph, grad_variables)
130 Variable._execution_engine.run_backward(
131 tensors, grad_tensors_, retain_graph, create_graph,
--> 132 allow_unreachable=True) # allow_unreachable flag
133
134
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
Your use of .data “breaks the computation graph,” so that no gradients are
backpropagated through loss_constrain. Therefore, when you only minimize loss_constrain you get the reported error. When you also minimize loss_mse (assuming that loss() returns total_loss) you do have gradients
that connect total_loss to your model parameters, so the error goes away.
However, loss_constrain is still disconnected from the computation graph,
so its gradients are not calculated and make no contribution to the gradients
calculated for total_loss. Therefore your gradient-descent optimization
knows nothing about loss_constrain and there will be no tendency for loss_constrain to be made smaller.
Also note that even if you remove .data, I believe that there is nothing that
prevents loss_constrain (the trace of the product of your two convolution
kernels) from becoming large and negative. So gradient descent will, roughly
speaking, ultimately drive one kernel off to +inf and the other off to -inf so
that loss_constrain becomes -inf (and dominates total_loss).
I don’t really follow what you are trying to do with loss_constrain, but
something like:
would at least prevent the -inf problem. (And, yes, I would include the
weighting factor wt_constrain so that you can adjust how strongly loss_constrain contributes to your overall loss.)
(One final note: Putting torch.manual_seed(1) in the constructor for Edge_Detector is not a good idea, as this sets the seed for the “global”
random number generator, affecting any other random-number calls, and
should you construct more than one Edge_Detector, the seed will be
reset. This could work for your use case, but is likely to become fragile as
you add more code to your system.)
thanks it ran without any error.but
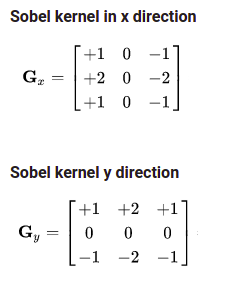
I want to learn the kernels given like this
or similar pattern like this
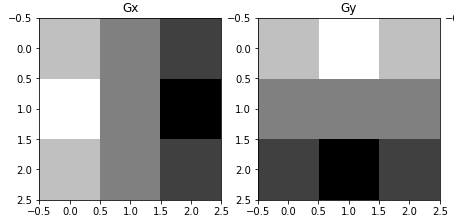
but after optimising i am getting like this.
If you want your kernels to be equal to the non-textual G_x and G_y you
gave, why don’t you just set them to be equal, rather than try to “learn”
them?
In a related point, it is true that your G_x and G_y satisfy your desired
constraint, and, indeed, loss_constrain takes on its minimum value of
zero with them. But so do many, many other pairs of 3x3 matrices. So
there is no reason that training with loss_constrain will result in kernels
that are close to G_x and G_y.