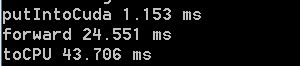
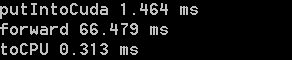I use a resnet to classify images, and find that it is slower to get the result back to the CPU than forward(), and far slower than put image data to CUDA as well.
Does anyone know how to increase the speed of transferring data back to cpu?
os:
windows 7
cuda9.2
libtorch1.0-nightly-release
visual studio 2019
relative code is as follows:
t1 = std::chrono::steady_clock::now();
at::Tensor tmpData2 = torch::from_blob(tmp, { resNetParam.batchSize, resNetParam.roiSize,resNetParam.roiSize,resNetParam.imgDepth }, torch::kFloat).to(m_device);
tmpData2 = tmpData2.permute({ 0, 3, 1, 2 });
t2 = std::chrono::steady_clock::now();
time_used = std::chrono::duration_cast<std::chrono::duration>(t2 - t1) * 1000;
printf(“putIntoCuda %.3f ms \n”, time_used);
t1 = std::chrono::steady_clock::now();
torch::Tensor out = m_model->forward({ tmpData2 }).toTensor();
t2 = std::chrono::steady_clock::now();
time_used = std::chrono::duration_cast<std::chrono::duration>(t2 - t1) * 1000;
printf(“forward %.3f ms \n”, time_used);
std::tuple<torch::Tensor, torch::Tensor> result = out.sort(-1, true);
t1 = std::chrono::steady_clock::now();
torch::Tensor sortedScores = std::get<0>(result).to(torch::kCPU);
torch::Tensor sortedIdx = std::get<1>(result).toType(torch::kInt32).to(torch::kCPU);
t2 = std::chrono::steady_clock::now();
time_used = std::chrono::duration_cast<std::chrono::duration>(t2 - t1) * 1000;
printf(“toCPU %.3f ms \n”, time_used);