I am interested in testing different kinds of architectures during training. For example, architecture 1 will have a specific architecture (conv-conv-pool) and then for the next epoch, I will modify it a little bit to become architecture 1 (conv-conv-pool-conv). This will go on until the the number of blocks is about 15 .
My problem is that I noticed that the memory goes up when I replace the model with a modified model. I checked the GPU memory allocation and it seems that the memory accepts the model as a new set of data instead of just replacing the old one. It wouldn’t be a problem if I am just testing one architecture at a time but I am using around 10 simultaneously.
Now I can just have batch_size = 4 instead of a faster 128 or else I will see CUDA out of memory
Please help me to release the memory by just replacing the old architecture data instead of adding on to it.
I guess you might observe memory fragmentation, i.e. the increased model size does not fit in the old memory block reserved for the smaller model, so a new one might be allocated.
Would it work if you start using the biggest model and shrink it?
I haven’t tested it yet, but it might be worth a try.
Thank you for your suggestion. However, I don’t have the biggest model because I am just trying to find out which model configuration will yield the highest accuracy for me and modify it. Is there a way to release the memory from the old memory block since I will train the modified model from scratch anyway?
The memory will be released. However, the new model might now “fit” into the old memory block, so that a new one might be needed.
You could check it by saving the old model’s state_dict and create the bigger model in a new script.
If the memory usage is significantly lower, you might indeed observe memory fragmentation issues.
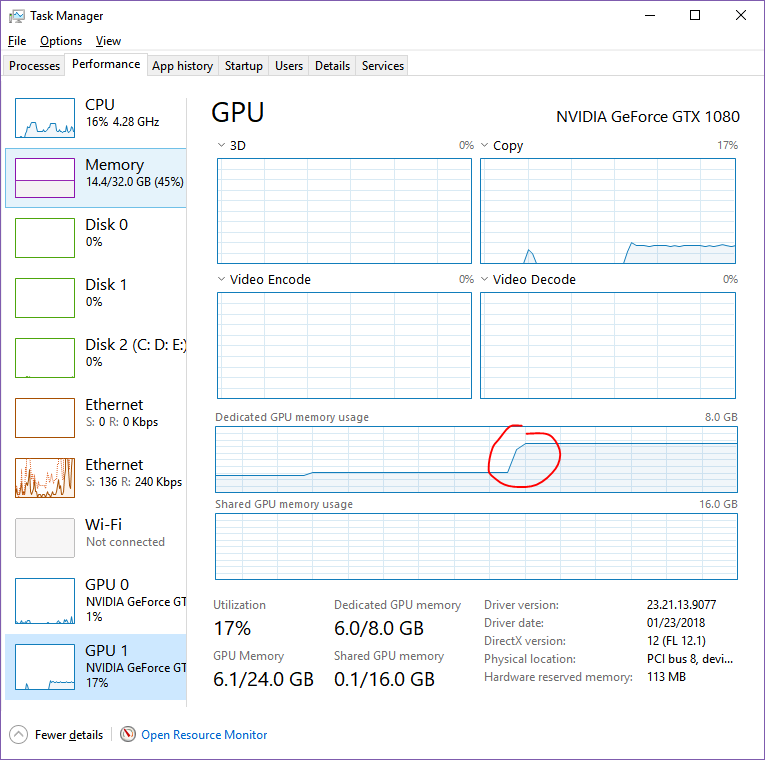
The bigger model created this huge spike on top of the old model’s memory block. I am not sure how this model can ‘fit’ into the old memory. Usually, I just restart the kernel to clear the memory. Is there a way to avoid this big spike when training a modified model?
The memory usage is most likely not showing the real used memory, but the cached memory by PyTorch.
Have a look at the Wikipedia article on Fragmentation. The table in " External fragmentation" gives a good idea of my assumption. While your old model might have taken the B block of memory, no new model bigger than B can fit in this gap, which will thus create a new block after C.