RuntimeError: [enforce fail at …\c10\core\CPUAllocator.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 48251840 bytes. Buy new RAM!
There is some data that I don’t need. So how to release them?
RuntimeError: [enforce fail at …\c10\core\CPUAllocator.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 48251840 bytes. Buy new RAM!
There is some data that I don’t need. So how to release them?
Hi,
For CPU data, just make sure that you cannot access them anymore.
As soon as a Tensor cannot be accessed, it is released.
Hi,albanD.
I understand what you said, but I’m not sure if I really don’t access them.
Take the following code as an example.
Could you give me some advice?
I omitted some parameters.
tensor = load_data()
for i in range(50):
{
tensor = gcn_model(tensor)
}
train(tensor)
In this code for example,
the Tensor0 returned by load_data() is associated with the name “tensor” on the first line.
On the first iteration of the loop, that Tensor0 is given to the gcn_model and a new Tensor1 is returned. It is associated with the name “tensor”.
At this point, no name refers to Tensor0, so it is deleted.
On the second iteration, Tensor1 is given to the model to create Tensor2. This new Tenso2 is associated with the name “tensor” and since Tensor1 cannot be accessed anymore, it is deleted.
Etc
Thank you, albanD~ By the way, I use psutil to find out how much memory I use. It seems that I still have a lot of free space to use. Why it prompted such error?
Which OS are you using? You may be limiting the amount of RAM the process is allowed to allocate?
I am using windows 10. Is there any solution to release the limitation? 
I have to admit I don’t know as I don’t use windows to run pytorch in general.
Maybe @peterjc123 would have a better idea here?
Would you please post the code?
I upload the code to github. Thank you~
Would you please refactor your code into the following style?
def xxx():
xxx
def yyy():
yyy
def main():
zzz
if __name__ == '__main__':
main()
I have refactored my code. It didn’t work 
Re-factoring for easy reading;
Would you please use objgraph for capturing more details? You can refer to this post: https://benbernardblog.com/tracking-down-a-freaky-python-memory-leak/.
I have added some comment on my code. Thank you for replying. Hope you can give me some advice.
OK, I also add some comment on my code for easy understanding.
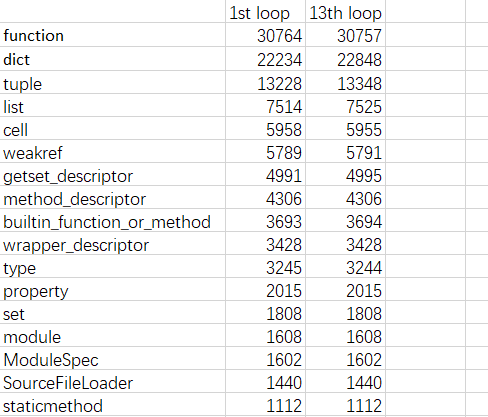
Some details by using objgraph. It seems that only dict increases a little.
In my computer, the code can execute active_learning() function 30 times around.
What about the count of the type Tensor?
import objgraph
objgraph.show_most_common_types(limit = 50)
function 30757
dict 22992
tuple 13382
list 7525
cell 5955
weakref 5793
getset_descriptor 4999
method_descriptor 4306
builtin_function_or_method 3694
wrapper_descriptor 3428
type 3244
property 2015
set 1808
module 1608
ModuleSpec 1602
SourceFileLoader 1440
LP_DGLArray 1121
staticmethod 1112
member_descriptor 735
WeakSet 555
classmethod 529
fused_cython_function 495
FontEntry 471
NDArray 435
itemgetter 405
instancemethod 350
MovedAttribute 342
cython_function_or_method 250
frozenset 224
CopyReduceBackward 216
Enum 205
It didn’t return the count of the type Tensor