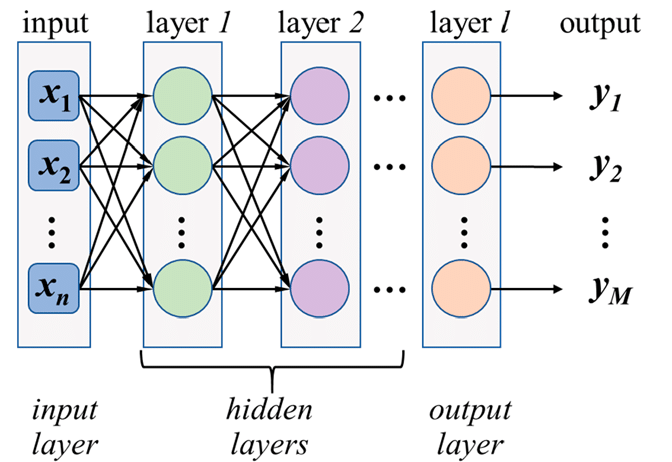
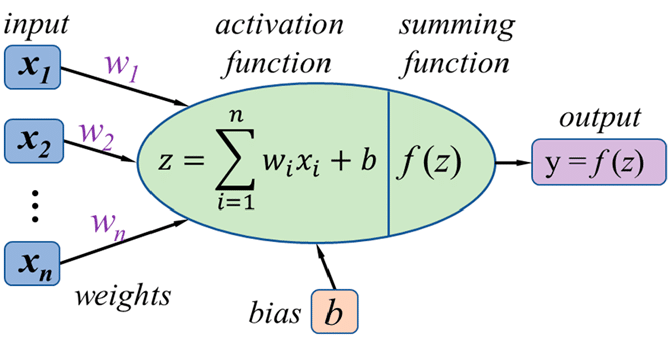
My network has convolution and fully connected layers, and I want to access each neuron’s weights and bias values. If I use
for name, param in network.named_parameters():
print(name, param.shape)
I get layer name and whether it is .weight or .bias tensor along with dimensions. How can I get each neuron’s dimensions along with its weights and bias term?
Just adding to @ptrblck’s answer, layer.weight[i] will give the weights of i'th neuron in a layer (both conv and linear) and layer.bias[i] will give the bias of i'th neuron.
Thanks, @ptrblck and @InnovArul. I want to know from @InnovArul if the convolution layer tensor’s .weight and .bias dimensions are [16,6,5,5] and [16] respectively, then are the neuron weights [i,:,:,:] and bias [i] where i = 1 to 16? Does it mean there are 16 neurons in the convolution layer?
@InnovArul, thanks for your help. However, I am confused with the neuron terminology answered at https://stackoverflow.com/a/52273707/15009452
The answer says that the number of neurons in a convolution layer depends on the size of the image. But, if the layer dimensions are [16,6,5,5], there are 6 input channels with 16 filters in the current layer producing 16 output channels having filter dimensions as 5x5. I don’t see any relation with the input size here. Can you please explain? It would be a great help.
ok. I understand the confusion. Maybe I contributed to it too.
Basically weight[i] is the way to get the parameters of the neuron. But the number of neuron calculations is different between the linear layer and conv layer.
Linear layer:
With respect to linear layers, it is clear how many neurons are present in the layer. (layer.weight.shape[0])
Conv layer:
With conv layers, the number of neurons calculation is a bit tricky which is explained in that StackOverflow post. I will rephrase it here as I understand.
In 2D conv layers, a neuron is an entity that looks at only a small slice of the input. Lets take the same example from StackOverflow where input size = 1x27x27 (channels=1, height=27, width=27), slice size = 1x3x3. So there are 9x9=81 slices of size 1x3x3 assuming non-overlapping slices.
Since conv layer holds the invariance property, a set of 81 neurons is supposed to share the same weights (i.e., layer.weight[i]). There can be N sets of 81 neurons in a conv layer (N = layer.weight.shape[0]). So the total number of neurons is N x 81.
@InnovArul, thanks again for a detailed response. So, as per my example of layer.weight.shape=[16,6,5,5], there must be N=16 sets of neurons. Kindly correct me if I am wrong. May I know how can we count the number of neurons in each set if we know only layer.weight.shape=[16,6,5,5]? Or do we need to consider the original input size and number of input sets to the layer (i.e., 6 in this case)?
@InnovArul@ptrblck I have a question linked to @Ajinkya.Bankar 's post. In a convolution layer where the weights are for instance as in @Ajinkya.Bankar case, of shape [16,6,5,5] and the bias of shape [16], before the output of this layer is given to an activation function, the same bias is applied to each of the neurons in a same filter (of shape [6,5,5])?
If that’s the case, is it possible (does it make sense?) to modify the bias applied to each filter so not all neurons of a same filter are added the same bias ?
Thanks for you reply.
I didn’t express myself well, I will rephrase my question. out_manual is of shape (2, 16, 22, 22) and bias of shape (16). If I’m not mistaken, the same value bias[i] is added to all values of out_manual[2, i, 22, 22]. Would it be possible instead (and does it make sense) to add a bias tensor of shape (1, 1, 22, 22) (with different values "inside it ") to out_manual[2, i, 22, 22]?
The bias tensor would thus be of shape (1, 16, 22, 22) instead of (16).
In my understanding, having a bias of shape (1, 1, 22, 22) would make the conv layer spatially dependent. i.e., the very property of translation invariance that the conv layer is known for, will be lost.
Does that make sense?