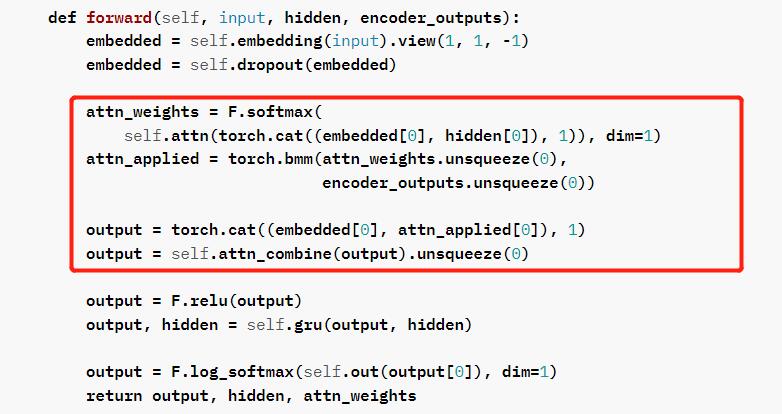
1st question: May I ask why you choose embedded[0] in self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1), and what do hidden[0] represent? Why not take embedded, hidden overall
2nd question: attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0))
Why is it multiplied after expansion in attn_weights.unsqueeze(0) dimension?
At least with respect to hidden, note that the output shape is (num_direction*num_layers, batch_size, hidden_size). Since the nn.GRU is unidirectional (num_directions=1) and has only one layer (num_layers=1), the shape simplifies to (1, batch_size, hidden_size). If I remember correctly, this tutorial uses only batch size of 1, so the shape is (1, 1, hidden_size)
This means that hidden[0] gives you the last hidden state. I would prefer hidden[-1]. In this case you could increase num_layers without changing the code.
The output shape of self.embedding should be (batch_size,seq_len, embed_dim). This after .view(1, 1, -1) the shape is (1, 1, batch_size*seq_len*embed_dim). If I remember correctly, this tutorial uses only batch size of 1, so the shape is (1, 1, seq_len*embed_dim). Also, this is the decoder where we generate words step by step, so the sequence length is also one, resulting in a shape of (1, 1, embed_dim)