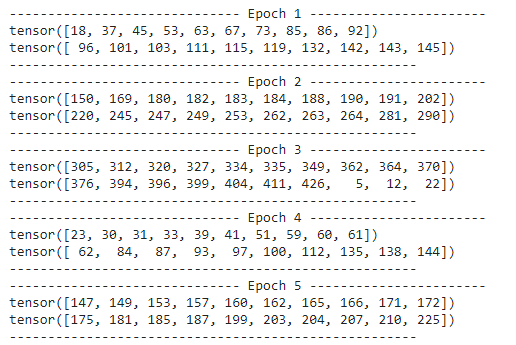However, I believe this solution is loading extra samples that end up not being used. I’d like to cycle through all the samples, across different epochs . For example if I have 1000 samples and I want 100 steps per epoch (batch size 1) , in 10 epochs the loader will cycle through all the samples and on epoch 11 it will load the first sample again. However following the solution from the other topic I believe some samples will be skipped and will never be used, because the dataloader already has loaded them but they end up not being trained on.
Yes, indeed the answer from my thread can pose a problem of uneven sampling. However, I found alternatives on setting manual step within epoch while still make dataloader goes over all data in dataset.
You could make another class that acts as wrapper over dataloader, in which you manually set how much step needed for given dataloader and number of steps
class LoaderWrapper:
def __init__(self, dataloader, n_step):
self.step = n_step
self.idx = 0
self.iter_loader = iter(loader)
def __iter__(self):
return self
def __len__(self):
return self.step
def __next__(self):
# if reached number of steps desired, stop
if self.idx == self.step:
self.idx = 0
raise StopIteration
else:
self.idx += 1
# while True
try:
return next(self.iter_loader)
except StopIteration:
# reinstate iter_loader, then continue
self.iter_loader = iter(self.loader)
return next(self.iter_loader)
Using toy sample, here’s what I got for using standard DataLoader
While this is my result using wrapper above
This might be less elegant that what you might expect, but hopefully this can solve your problem
However I need to ignore whatever iter((list) this sampler generates and instead control the loaded samples in my dataset class with a few class members. That makes the idx parameter passed to getitem useless. This code was modified from mmdetection.
def get_curr_idx(self):
if self.idx == 0:
random.shuffle(self.order)
curr_idx = self.order[self.idx]
self.idx = (self.idx + 1) % self.total_samples
return curr_idx
def __getitem__(self, idx):
curr_idx = self.get_curr_idx()
if self.test_mode:
return self.prepare_test_img(curr_idx)
while True:
data = self.prepare_train_img(curr_idx)
if data is None:
curr_idx = self.get_curr_idx()
else:
return data
I had a similar problem and I dealt with it by defining the number of iterations and an epoch counter then using them to dedicate a sample’s index and the length of the data loader. Kindly mind the answer was not fully tested, so any recommendation, fixation, or feedback is really appreciated.
class CustomImageDataset(Dataset):
def __init__(self, epoch, annotations_file, img_dir, transform=None, target_transform=None):
self.img_labels = pd.read_csv(annotations_file)
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
self.epoch = epoch ## step 1
self.iter = 100 ## step 2
def __len__(self):
return self.iter ## step 3 (set loader length to desired number of iterations)
def __getitem__(self, idx):
## step 4 (find new idx)
new_idx = idx + (self.iter*self.epoch)
## step 5 (handle wrap around case)
if new_idx >= len(self.img_labels):
new_idx = new_idx % len(self.img_labels)
## step 6 (the rest of your code comes here. mind that here we use new_idx to locate a data point)
img_path = os.path.join(self.img_dir, self.img_labels.iloc[new_idx, 0])
image = read_image(img_path)
label = self.img_labels.iloc[new_idx, 1]
return image, label
Obviously, this means that the dataset and dataloader must be defined within the training loop such that the parameter epoch is updated at the start of a new training epoch. e.g.,: