Hi,
I am trying to perform a custom convolution operation. I am using a c++ extension to perform the convolution operation using a lookup table. The trained model is an Encoder-Decoder architecture, with encoder as DenseNet-161.
Following are the input and weight dim for the 1st layer of decoder, over which I’m doing custom convolution op.
input dimension = [1,2208,15,20]
kernel dim = [1104,2208,1,1]
And this is the manner in which I reshape them and call the c++ extension for custom conv2d function:
img = F.pad(input= input, pad= (pad, pad, pad, pad), mode='constant', value= 0)
patches = img.unfold(2,kh,dh).unfold(3,kw,dw).reshape(batch_size, in_channels*kh*kw, -1)
result = torch.zeros(batch_size, out_channel, out_h, out_w)
kernel = kernel.reshape(out_channel, -1)
result = custom_conv.conv_two_d(patches, kernel, lookup_table, out_h, out_w)
The c++ implementation is given below:
#include <torch/extension.h>
#include <torch/types.h>
#include <vector>
#include <THC/THC.h>
#include <iostream>
#include <ATen/NativeFunctions.h>
#include <ATen/Config.h>
#include <cuda_runtime_api.h>
#include<cmath>
#include<iostream>
#include<cstdlib>
torch::Tensor conv_two_d(torch::Tensor input,
torch::Tensor weights,
torch::Tensor lookup_table,
int64_t outh, int64_t outw) {
int64_t batch_size = input.size(0);
int64_t out_channels = weights.size(0);
torch::Tensor output = torch::zeros(torch::IntArrayRef({batch_size, out_channels, outh, outw})).cuda();
torch::Tensor result = torch::zeros(torch::IntArrayRef({out_channels, outh*outw})).cuda();
input = input.cuda();
weights = weights.cuda();
int sign=0;
time_t start, end;
std::cout<<"\n Starting..."<<std::endl;
for (int elt=0; elt<batch_size;elt++){
torch::Tensor input_n = input[elt].cuda();
for(int i=0; i<weights.size(0); i++){
start = time(NULL);
for(int j=0; j<input_n.size(1); j++){
int64_t r=0;
for(int k=0; k<weights.size(1);k++){
float t1 = weights[i][k].item<float>();
float t2 = input_n[k][j].item<float>();
t1 = round(t1*1000); t2 = round(t2*1000);
if(t1>255){t1=255;} if(t1<-255){t1=-255;}
if(t2>255){t2=255;} if(t2<-255){t2=-255;}
if(t1>0 && t2>0 || t1<0 && t2<0){
t1=abs(t1); t2=abs(t2);
sign=1;
}
if(t1<0 && t2>0 || t1>0 && t2<0){
t1=abs(t1); t2=abs(t2);
sign=-1;
}
r+= lookup_table[t1][t2].item<int>()*sign;
}
result[i][j] = r/1000000;
}
end = time(NULL);
std::cout<<"Time taken for iteration:"<<i<<" in batch:"<<elt<<" is:"<<end-start<<std::endl;
}
output[elt].add_(result.reshape(torch::IntArrayRef({out_channels, outh, outw})));
}
return output;
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m){
m.def("conv_two_d", &conv_two_d,"conv forward (CUDA)");
}
The time taken to complete each iteration is ~10-11 seconds… which in turn takes ~3.5 hrs to complete inference over a single image. (as shown below)
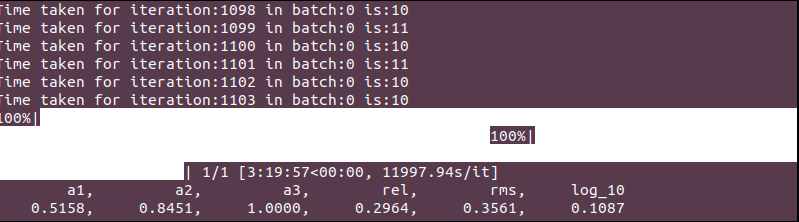
My doubts are:
1) What can I possibly do to increase the speed at which the inference is done?
I have looked into the possibility of FFT_conv but I got to know that it’s mostly for larger kernels and images and saw it mentioned that, performing FFT_conv on smaller kernels might actually slow down the convolution process further.
2) Is there a way in which I can reduce the inference time for smaller kernels?
The model on which I am doing inference has only 1x1 and 3x3 kernels.
TIA