Hi there! I think using an autoencoder is the right path for me, but I am wondering what might be the best way of achieving the desired result.
I have some features (of length 279) for objects which are created by a deep model for ~10 mio objects. as these features are created in a self-supervised way, they hold some redundant and undesired information. The end goal is to further model these features for downstream tasks which would benefit from having fewer features. Therefore I find autoencoders enticing, for simply reducing the number of features (not for generative purposes) but my main question is this: Would there be a way of steering the latent representation towards discarding the unwanted information?
if an autoencoder is trained to perfectly reconstruct its inputs, it will of course include the unwanted information unless its told otherwise. Therefore, would it be possible for me to label the data such that samples that are somewhat different in the 279-feature representation get the same label and this could guide the autoencoder to represent them together? Off the top of my head, having a model that encodes a reduced latent representation and uses it to predict labelled classes could be promising.
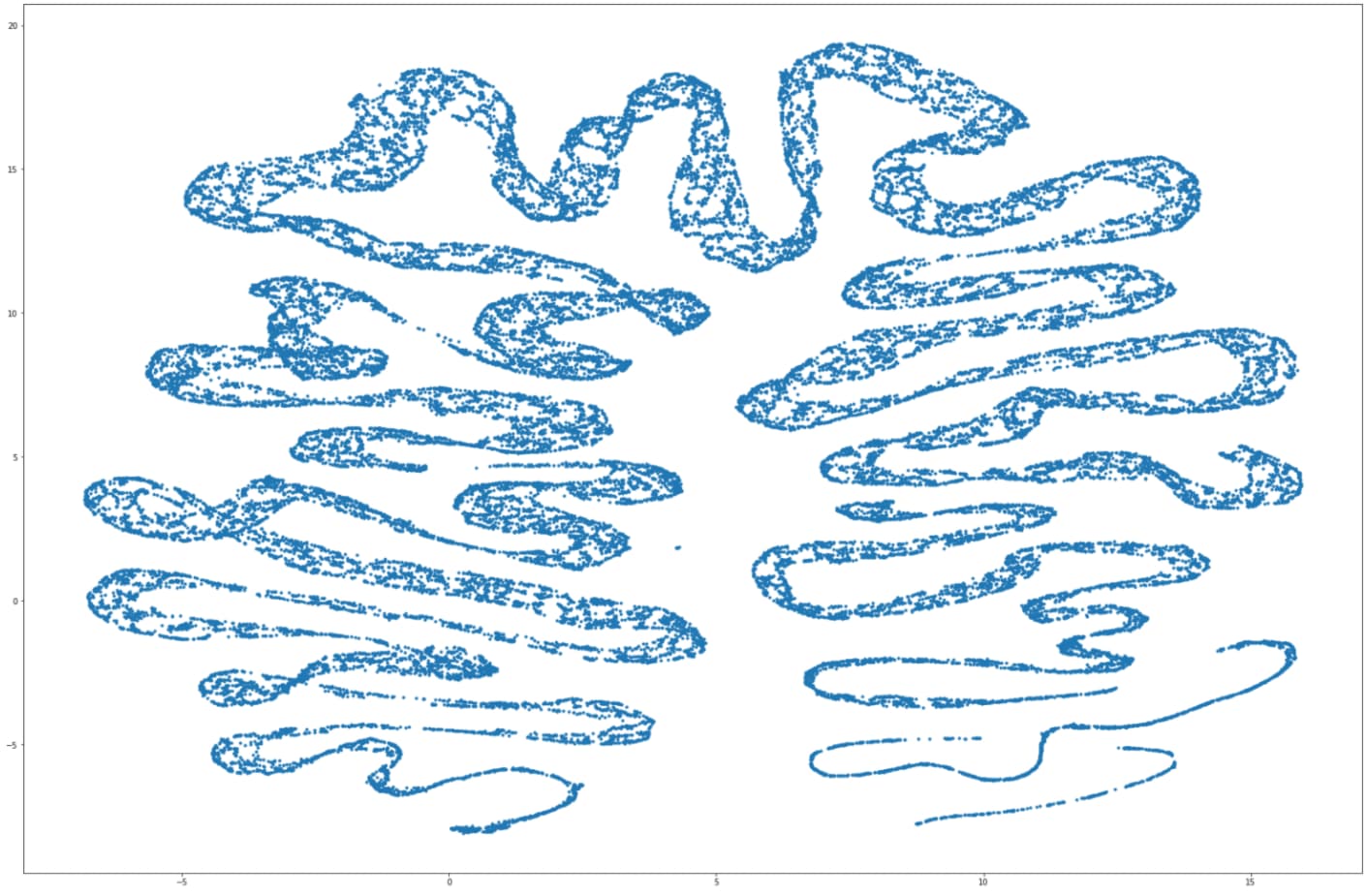
Below is a UMAP of ~10K objects.
The three large clusters in the top right are mostly desired to be modelled as the same.
That sounds generally like a valid idea and I would imagine you could use the latent tensor and feed it into a classifier to train the generator using both paths, the classifier as well as the decoder.
Okay so I have trained the first autoencoder only with reconstruction as objective for now. Its based on 50K samples of original size 588 which is mapped to 18 and then reconstructed to 588. I have across 3 epochs achieved between 0.01 and 0.04 MSE on the trainingset. But I am experiencing some odd behavior when I look at the UMAPs.
The “original data” is exactly what the network is given. all of the UMAPs are computed with the same settings. All data have the same scale/range (0-1), data type (float64) etc. I noticed that my original data has more decimals, but rounding it to same decimals made no difference.
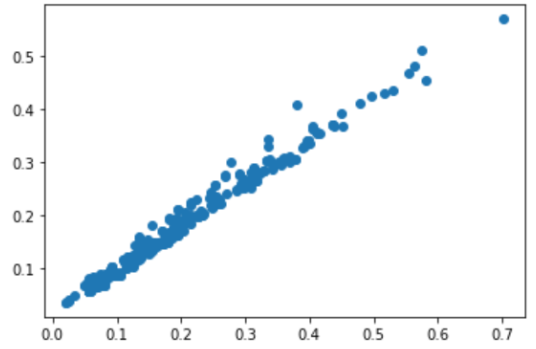
also as a sanity check, heres a scatter of original data vs reconstructed for a single sample:
(generally the reconstructed overestimates the values slightly but there is a great correlation coefficient)
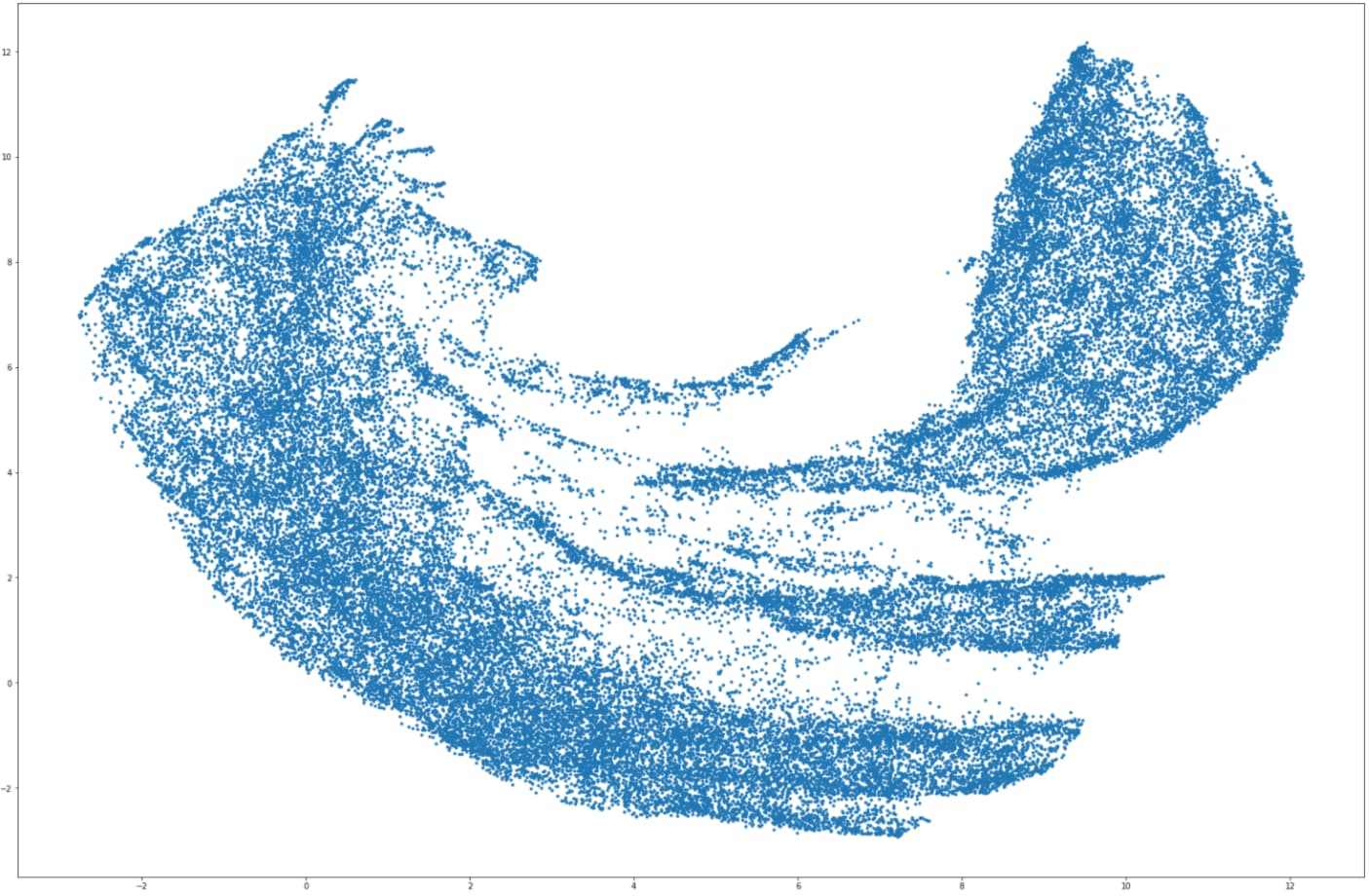
EDIT,EDIT: I cant reproduce what I’ve written below, so probably normalization wasnt the key. At the moment I guess that while the network is producing a low MSE, it still introduces some dynamic which UMAP picks up on and maps instead of the topology of the original data.
Allow me to answer the question myself… I remember one of my students showed me such a UMAP wrt normalization of data so I tried to add in LayerNorm into the encoder and decoder.
Here is a UMAP of the reconstructed samples where the model includes LayerNorm between the Linear and ReLU: