I’m trying to implement my own Conv2d layer for self-study and educational purposes. I feel quite confident that I understand the basic idea and steps – images like the one below illustrate the steps pretty well:
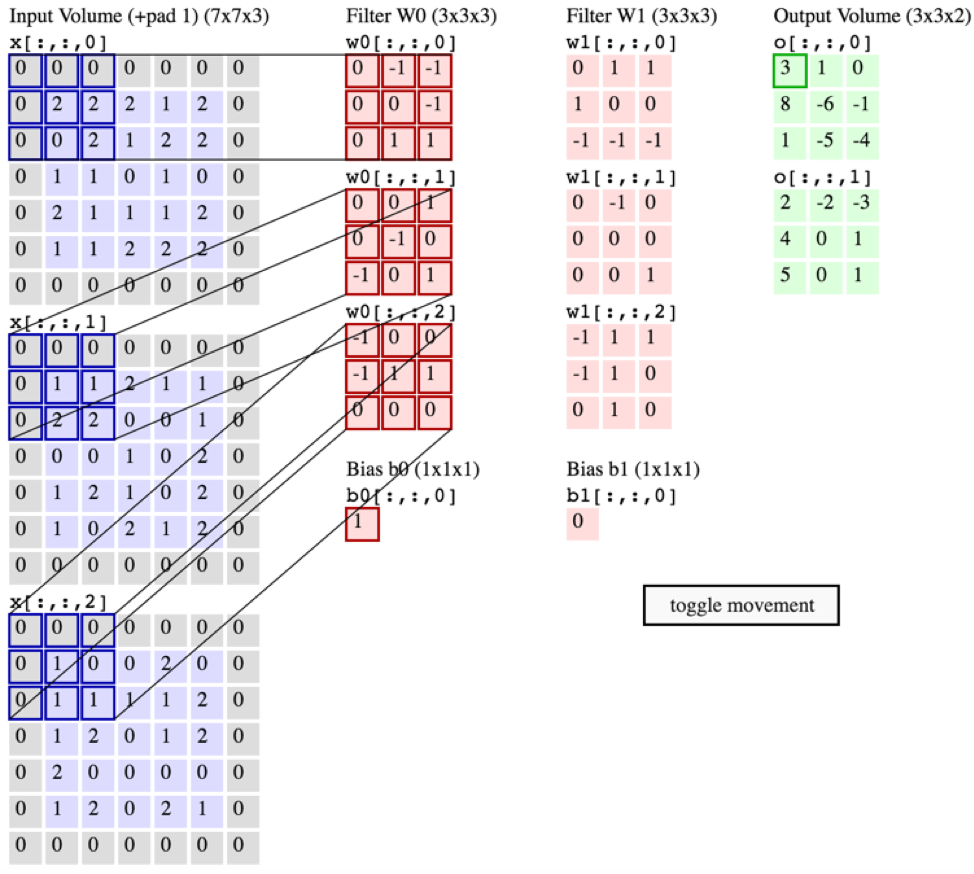
My current implementations looks as follows:
import torch
import torch.nn as nn
import numpy as np
class VanillaConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super().__init__()
self.pad, self.stride = padding, stride
# Note: kernel_size is always a tuple (not an int like for nn.Conv2d)
self.filter_weights = nn.Parameter(torch.rand(out_channels, in_channels, kernel_size[0], kernel_size[1]))
self.filter_biases = nn.Parameter(torch.rand(out_channels, ))
def forward(self, X, padding_value=0):
N, C, H, W = X.shape
F, C, HH, WW = self.filter_weights.shape
# Pad intputs
X_pad = nn.functional.pad(X, (self.pad, self.pad, self.pad, self.pad), mode='constant', value=padding_value)
# Get the height and weight of the padded inputs
_, _, H_pad, W_pad = X_pad.shape
# We need to compute the height and width of the outputs based on
# * Size of filters
# * Padding
# * Stride
H_out = 1 + (H + 2*self.pad - HH) // self.stride
W_out = 1 + (W + 2*self.pad - WW) // self.stride
# Define the tensor that will hold the output of the layer
out = torch.zeros((N,F,H_out,W_out))
########################################################################################################
# Perform convolution operations
########################################################################################################
# Looper over each sample in batch
for n in range(N):
# For each sample, loop over each filter
for f in range(F):
# For each filter, perform convolution (nested loops do the sliding window)
for h in range(H_out):
for w in range(W_out):
h_, w_ = h*self.stride, w*self.stride
# Get the current patches (i.e., the patches for all channels of current sample)
patches = X_pad[n, :, h_:h_+HH, w_:w_+WW] # patches.shape: (C,HH,WW) same as self.filters[f]
# Multiple all channels and respective filter element-wise and sum all up
out[n, f, h, w] = torch.sum(patches * self.filter_weights[f]) + self.filter_biases[f]
########################################################################################################
return out
Please note that the code is for understanding. I know it’s horrible from a performance point of view, and it’s never intended to be used for actually training a model with it. It’s only important that it performs the convolution(s) as illustrated in the figure above.
I mainly adopted available solutions of Assignment 2 of the Stanford CS321n course; this solution I mainly aligned to. However, this assignment requires an implementation purely using NumPy incl. an implementation of the backward pass. I want to skip this part, and therefore want to implement the layer in Python to make use of autograd. I like to think my code is kind of correct, but I cannot fully convince myself.
Now, I’ve tried to test with a basic example using the MNIST dataset; adopted this tutorial. When change the code for the model accordingly as follows.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
#self.conv1 = nn.Conv2d(1, 10, kernel_size=(5,5)) # orginal code using nn.Conv2d
#self.conv2 = nn.Conv2d(10, 20, kernel_size=(5,5)) # which works just fine
self.conv1 = VanillaConv2d(1, 10, kernel_size=(5,5))
self.conv2 = VanillaConv2d(10, 20, kernel_size=(5,5))
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
the training works but, of course, painfully slow. In fact, so slow that I can’t really use it – I don’t even have a GPU at hand :(. I tried with very small toy data which seem to work. But I fear the the toy dataset is so simple that all learning is done by the fully connected layers, independent what the convolution layers are actually doing.
How can I best test this? Or more basically, is my approach reasonable at all? I’m not sure if autograd handles the sliding window for the convolution as I would expect.
EDIT: I’ve fixed the bug in the forward() method to work with strides other then 1.