This is a graph of the GPU usage over time that when I run my code:
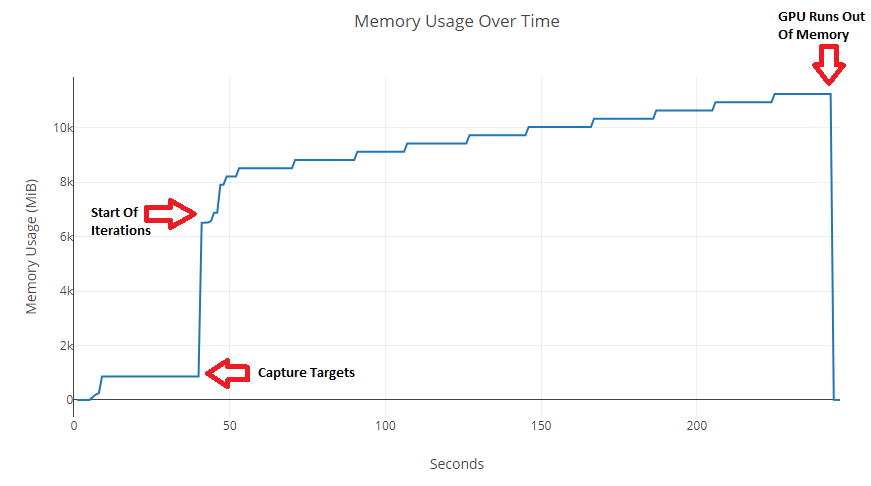
I’ve tried using del on Variables that I thought were causing the issue, but that didn’t seem to help. I also tried using gc.collect(), but that did nothing as well.
This function is where my iterations occur:
def closure()
optimizer.zero_grad()
net(img)
loss = 0
for mod in content_losses:
loss += mod.loss
for mod in style_losses:
loss += mod.loss
loss.backward(retain_graph=True)
#Save image function
#Print loss values function
return loss
optimizer.step(closure)
The optimizer is:
optimizer = optim.LBFGS([img], max_iter = 200, tolerance_change = -1, tolerance_grad = -1)
I can’t seem to figure out what is causing the memory usage to increase about every 10 iterations. Are there any easy to use tools that would allow me to discover the Variable(s) and/or line(s) of code which are responsible for this ever increasing GPU usage?