I attempted to replace the FFN in Transformer with MoE (implemented by fairscale). I am curious about how to integrate MoE and FSDP together. The data parallel groups for different parameters in the model are not the same, and FSDP does not provide an interface to assign different dp groups to different parameters.
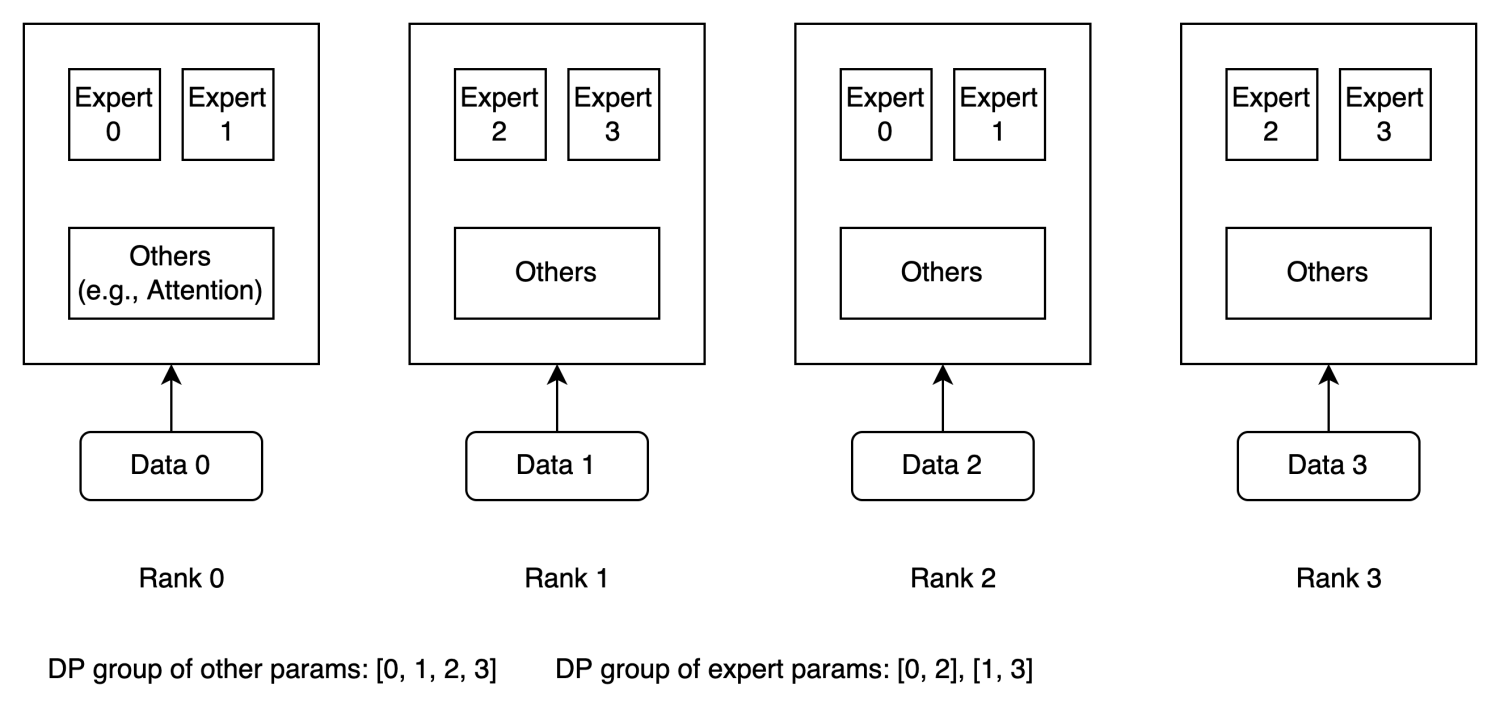
For example, consider the diagram below: the model has four experts, with two placed on each rank, and the parallelism of the experts is 2. In this case, the data parallel group for non-expert parameters (such as attention and word embedding) is [0, 1, 2, 3], while the dp groups for experts are [0, 2] and [1, 3].
Reference: