Hello, everyone!
I am working to build multi-branch network.
Here is what I am working on.
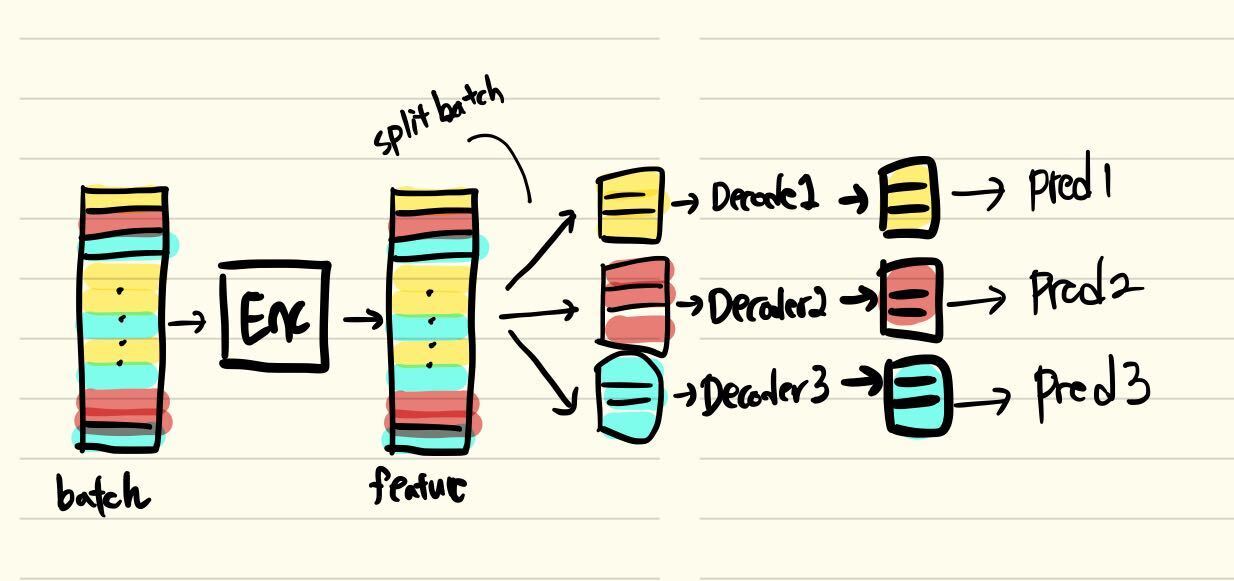
Each data sample in the batch has its own class, so each sample goes into a decoder of the same class as itself.
How to train this kind of network?
Here is a training step in my current code.
params = list(Encoder.parameters()) + list(Decoder1.parameters()) \
+ list(Decoder2.parameters()) + list(Decoder3.parameters())
optim = torch.optim.Adadelta(params, learning_rate)
encoder_output = Encoder(input)
optim.zero_grad()
loss_1, loss_2, loss_3 = 0, 0, 0
# split batch
if encoder_output[1_batch_ind].shape[0] != 0:
output1 = Decoder1(encoder_output[1_batch_ind])
loss_1 = loss_fn(output1, ground_truth[1_batch_ind])
if encoder_output[2_batch_ind].shape[0] != 0:
output2 = Decoder2(encoder_output[2_batch_ind])
loss_2 = loss_fn(output2, ground_truth[2_batch_ind])
if encoder_output[3_batch_ind].shape[0] != 0:
output3 = Decoder3(encoder_output[3_batch_ind])
loss_3 = loss_fn(output3, ground_truth[3_batch_ind])
loss = loss_1 + loss_2 + loss_3
loss.backward()
optim.step()
What I have expected is each loss_# is backpropagated through each Decoder#, only and Encoder is trained by a total sum of loss, which means the backpropagation happens like
loss_# → Decoder#,
total_loss → Encoder.
Does the code above run as I have expected??