Hi, I am just a beginner of PyTorch, even a beginner of Python. So this question may too simple for you but I really want to get some help.
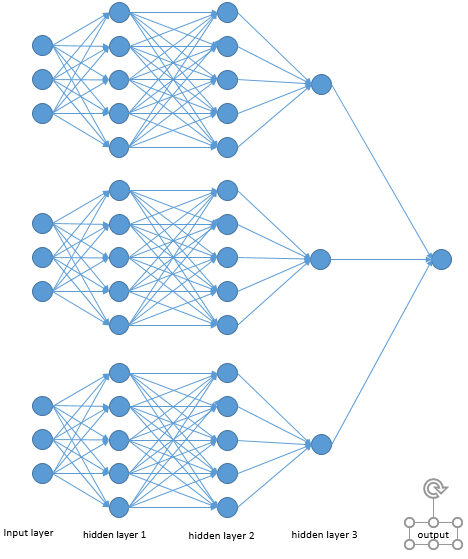
I want to train a neural network which is included sub-networks. It looks something like that.
In my opinion, this network could be implemented by constructing three simple fully-connection neural networks.
My implementation is:
#firstly, define the simple NN
class Net(nn.Module):
def __init__(self,n_input,n_hidden1,n_hidden2):
super(Net, self).__init__()
self.hidden1 = nn.Linear(n_input,n_hidden1)
self.hidden2 = nn.Linear(n_hidden1,n_hidden2)
self.output = nn.Linear(n_hidden2,1)
def forward(self,x):
x = F.tanh(self.hidden1(x))
x = F.tanh(self.hidden2(x))
x = self.output(x)
return x
#construct 3 same nets
net = []
for i in range(3):
net.append(Net(3,5,5))
# define loss function and optimizer
optimizer = []
for i in range(3):
optimizer.append(torch.optim.SGD(net[i].parameters(), lr = 0.2))
loss_func = torch.nn.MSELoss()
#training neural network
for step in range(300): #training circles
for i in range(3):
output[:, i] = net[i](input[i, :, :])
prediction = torch.sum(output,1)
loss = loss_func(prediction,target)
for i in range(3):
optimizer[i].zero_grad()
loss.backward(retain_variables=True)
for i in range(3):
optimizer[i].step()
after several circles, all output value become to the same value.
There must something wrong with my code. Could anyone give me some help?
Or are there any better way to implement this network?
Thanks a lot.
Oh, I have tried using only one optimizer. But
net = []
is a list but not torch.autograd.Variable, So there are no parameters in net. PyTorch reported as an error for one optimizer.
Would the network learn different weights when using these seperate optimizers which all optimize the same loss, or is it just a matter of style or performance?
Hi, I would like to share my experience in case it might be helpful for other newbies (like me) around here.
I created a bigger NN model (nn.Module child class) containing 2 smaller subnetworks.
I just defined first the simple subnetwork as a nn.module child class.
Then in the init method definition of the bigger model class, I just called/defined the 2 submodels.
They appear of course also in the forward method (with same input x in my case).
You can then add another layer to merge the solutions coming from subnetworks, in case you need.
Training goes than as usual.
Hello Andrea, I have tried implementing the solution you have offered but something is bugging me.
In my case, I have two seperate networks as subnetworks and their output form a loss function together. I have initialized those subnetworks in a larger nn.Module child class and included them in the forward.
However, my reason for applying this was that I have a single GPU which seems to be under allocated (4 GiB allocation in a 32 GiB GPU) and I don’t want to allocate another GPU. But it seems like I am having problems at parallelization of my subnetworks. I was hoping that PyTorch internally allows parallelization by building the computation graph but it seems like something is wrong. My training with two subnetworks takes more than twice duration. Have you observed a similar situation?