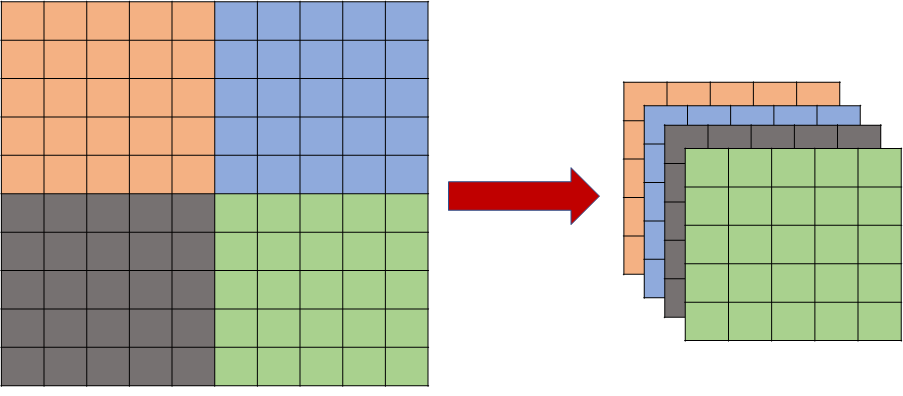
So a convolution2d operator is essentially a simple matrix multiplication over a flattened patch of an image. If your entire image is [b,1,10,10] and you choose convolution with kernel W of size (5,5) with output size (d) and with stride=5, it will do the following 4 operations, say the output is O of size [b,d,2,2]:
O[b_i,0:d,0,0] = W * X[b_i,:,:5,:5].view(1*5*5) where W is size (d,1x5x5)
O[b_i,0:d,0,1] = W * X[b_i,:,:5,5:].view(1*5*5)
etc.
So if you set output dimension to same as input dimension (d = 1x5x5) and set it to Identity matrix it will preserve all the information. And you can then reshape it back into (5,5) and have the same image.
So your output O is of size (b,1x5x5,2,2). Flatten last two dimensions -> (b,5x5,4). Then transpose -> (b,4,5x5). Then reshape again -> (b,4,5,5), and voila.
But slicing much less confusing, not sure about the speed of this vs the for loop with slicing.