I have a long fomular:
tensor a = […]
tensor b = […]
cosin_a = cosin(a)
cosin_b = cosin(b)
…
output = cosin_a + consin_b)
Final = loss(output, target)
grad_ = torch.autograd.grad(output, (tensor a , tensor b), create_graph=True, retain_graph=True)
After that, I got “One of the differentiated Tensors appears to not have been used in the graph”
But If I change tensor a and tensor b by other parameter directly to out such a cosin_a or consin(b) and I got grad_ dimension of output different with tensor a and b and I don’t know how to update variable a and b to optimize loss,
Thank you for considering my issue!
This means that there is no autograd connection (the .grad_fns of the tensor) between the input and the output.
This can happen for example if you at some point only conditionally use one or the other.
So this error can be suppressed by passing allow_unused=True to torch.autograd.grad. However, I always recommend that to find out why exactly this situation happens and add a comment to the invocation detailing that reason to make sure that it is not a bug in your code. In my personal experience, articulating the reasons of why certain default behaviour is not applicable in my particular case helps me a lot with sorting out whether it is an error on my side or a case where the behaviour should legitimately deviate from the default.
You could also try to change your computation to do this differently (e.g. use torch.where instead of an if ... else clause (this can also be computationally more efficient), but it would really depend on the details of your situation whether this is a good course of action.
Best regards
Thomas
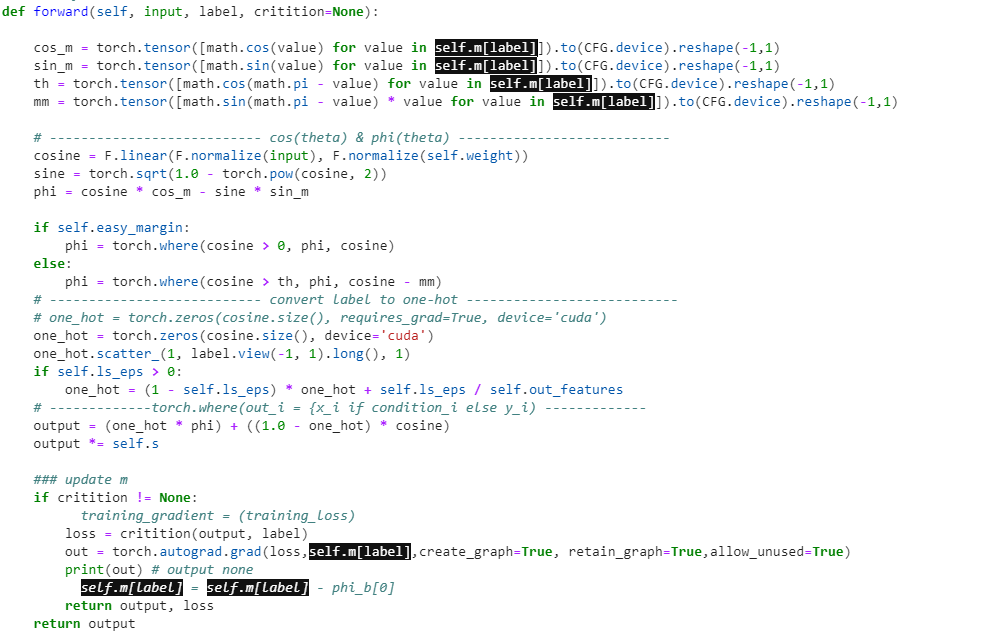
In my code, I want to minimize loss depend on self.m variable at list index “label”. And I got “One of the differentiated Tensors appears to not have been used in the graph” after that I set allow_unused=True then I got the output of grad is None. I don’t know to fix it, And I think all of steps use variable self.m. and variable easy_margin default False. Thank you for your support!
- Autograd only works with torch.sin / torch.cos, not math.cos. But then you don’t need to go via enumeration but can just use the pointwise function on the tensor.
- You probably want to differentiate w.r.t. self.m itself and then take the index (unless self.m is prohibitively large, in which case you should assign
self.m[label]to a Python variable at the very top of your function and then re-use that).
This should get you a bit further.
P.S.: With triple backticks (```) before and after your code and the code as text, it is easier to copy-paste things for rearranging.
1 Like
class ArcMarginProduct(nn.Module):
r"""Implement of large margin arc distance: :
Args:
in_features: size of each input sample
out_features: size of each output sample
s: norm of input feature
m: margin
cos(theta + m)
"""
def __init__(self, in_features, out_features, s=30.0, m=0.50, easy_margin=False, ls_eps=0.0):
super(ArcMarginProduct, self).__init__()
self.in_features = torch.tensor(in_features)
self.out_features = torch.tensor(out_features)
self.s = torch.tensor(s)
self.m = torch.repeat_interleave(torch.tensor([m],requires_grad=True),CFG.num_classes)
self.ls_eps = torch.tensor(ls_eps) # label smoothing
self.weight = Parameter(torch.FloatTensor(out_features, in_features))
nn.init.xavier_uniform_(self.weight)
self.easy_margin = easy_margin
self.torch_pi = torch.acos(torch.zeros(1))*2
# self.critition = critition
def forward(self, input, label, critition=None):
m = self.m[label]
cos_m = torch.tensor([torch.cos(value) for value in m]).to(CFG.device).reshape(-1,1)
sin_m = torch.tensor([torch.sin(value) for value in m]).to(CFG.device).reshape(-1,1)
th = torch.tensor([torch.cos(torch.sub(self.torch_pi, value)) for value in m]).to(CFG.device).reshape(-1,1)
mm = torch.tensor([torch.mul(torch.sin(torch.sub(self.torch_pi, value)), value) for value in m]).to(CFG.device).reshape(-1,1)
# --------------------------- cos(theta) & phi(theta) ---------------------------
cosine = F.linear(F.normalize(input), F.normalize(self.weight))
sine = torch.sqrt(torch.sub(1.0,torch.pow(cosine, 2)))
phi = torch.sub(torch.mul(cosine,cos_m),torch.mul(sine,sin_m))
if self.easy_margin:
phi = torch.where(cosine > 0, phi, cosine)
else:
phi = torch.where(cosine > th, phi, torch.sub(cosine,mm))
# --------------------------- convert label to one-hot ---------------------------
# one_hot = torch.zeros(cosine.size(), requires_grad=True, device='cuda')
one_hot = torch.zeros(cosine.size(), device='cuda')
one_hot.scatter_(1, label.view(-1, 1).long(), 1)
if self.ls_eps > 0:
one_hot = torch.add(torch.mul(torch.sub(1, self.ls_eps), one_hot), torch.div(self.ls_eps, self.out_features))
# -------------torch.where(out_i = {x_i if condition_i else y_i) -------------
output = torch.add(torch.mul(one_hot, phi), torch.mul(torch.sub(1.0,one_hot),cosine))
output = torch.mul(output, self.s)
### update m
if critition != None:
# training_gradient = (training_loss)
loss = critition(output, label)
out = torch.autograd.grad(loss, m , create_graph=True, retain_graph=True,allow_unused=True)
print(out) # output none
# self.m[label] = self.m[label] - phi_b[0]
return output, loss
return output
I replace all operator *,-,/,+ to torch pointwise, and assing m = self.m[index] and resuse it. And I got the same error, output of torch grad equal “None”.  . Thank you for your work.
. Thank you for your work.
In the end, my issue is solved by fix some initial variables. Thank for your work!
Congrats, I am glad you figured it out!
1 Like