I am using WandB to track pytorch machine learning projects. I am using an Nvidia A100 GPU hosted with Vultr. I don’t know if this is a question for this forum, but I figured that it would at least be down the alley of the people on the pytorch forums.
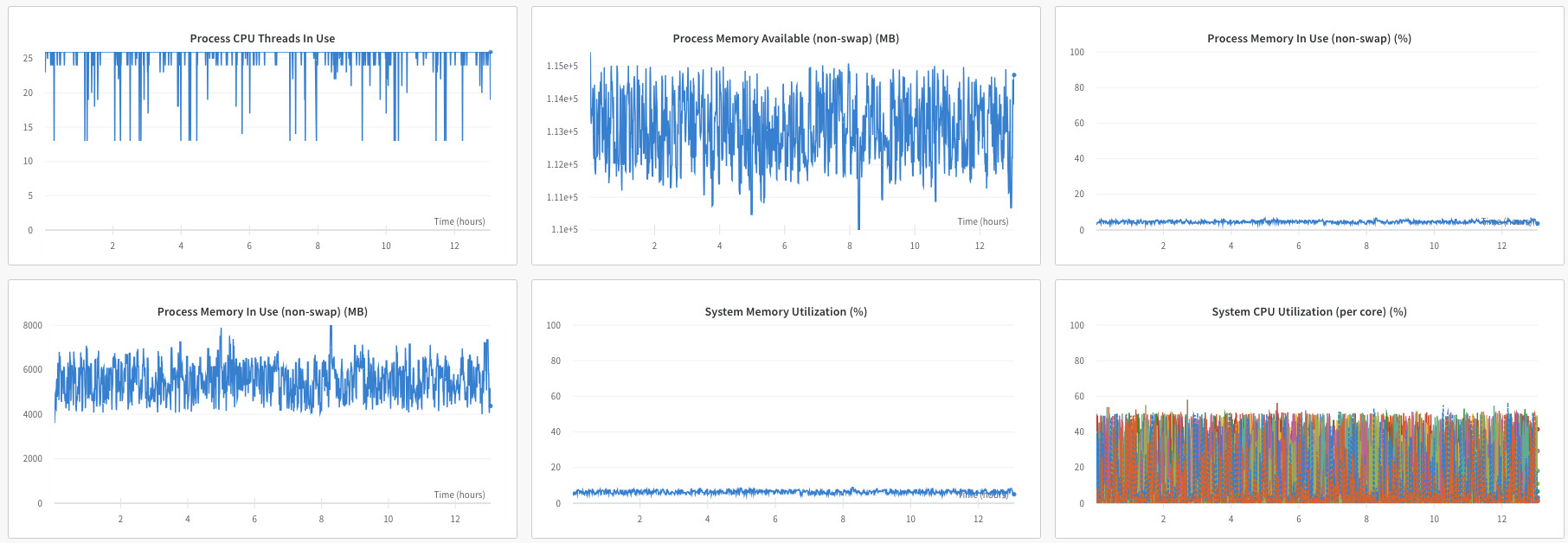
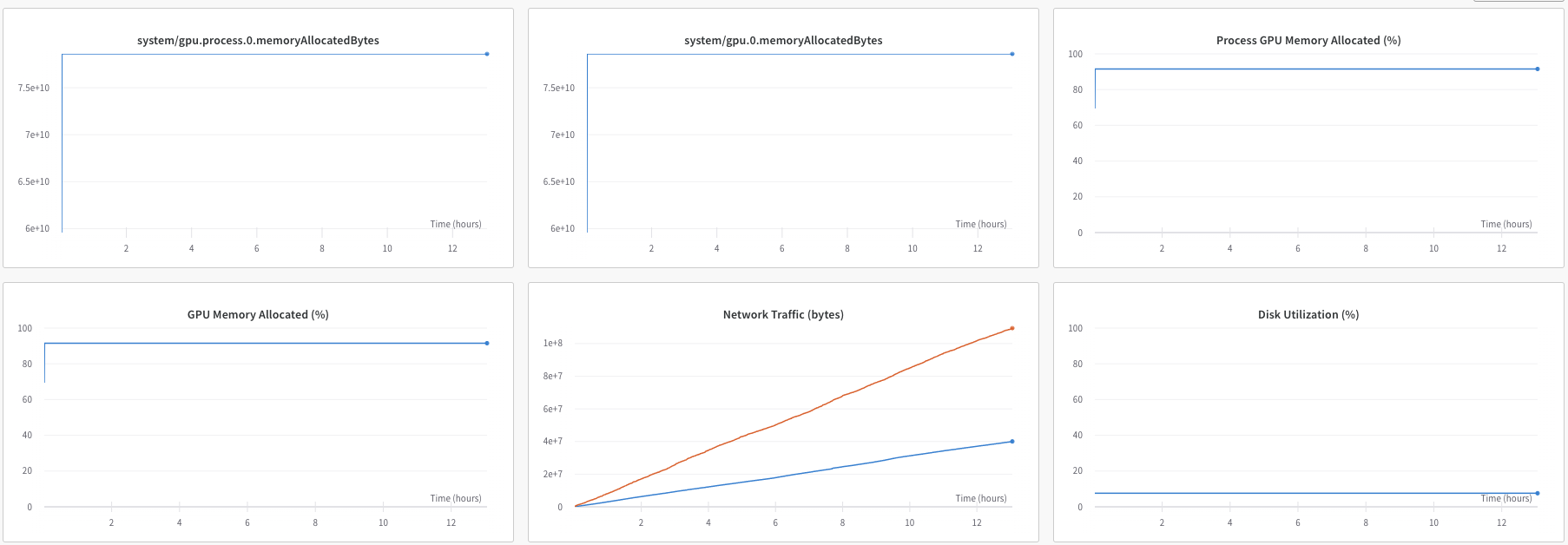
On the WandB system reports, it shows that I am using 90% of the GPU processing memory, but only 15% of the process memory. I want to make sure that I am using my VM to it’s full extent, and am curious if there is a way to use more process memory to speed up training.
I imagine this is an involved question, so if anyone has any resources they can point me to to learn more about this topic I would be very grateful. The only insight I have is that the optimizer states and weights are all stored on the GPU for quick training. What I am unsure of, is if there is a pytorch method to offload some of that work to the CPU to increase speed, or if CPU use for training neural networks is more of a memory saver, but will slow down training speed.
Could you describe the difference between “processing” and “process” memory?
These are the reports that Wandb is giving. I am assuming that when it says process memory and system memory it is referring to the cpu, but I am not entirely sure. Hopefully this provides more context.
Thus far, the only forms of parallelism I know to use on a single GPU is increasing batch size, and increase the number of workers loading the data. Obviously, increasing batch size doesn’t do anything to offload memory to the cpu, or utilize better the cpu processing power, but it does maximize GPU usage.
The system I am using has 12 Vcpus, and so I set my number of workers to 12, as per the warning signal pytorch gives when putting num_workers > number of cpus available.
I’m not familiar with wandb, but if I understand your question correctly you want to offload data to the CPU to be able to utilize these cores. In that case you could use these functions to offload data to the host to save memory and could move it manually via to("cpu") and execute any CPU layers on this data afterwards. Note that you would usually not use this approach as it will create a slowdown, but I’m also not familiar with your setup and use case.