I want to use nn.parallel.DistributedDataParallel to train my model on single machine with 8 2080TI GPUs. I set distributed config as torch.distributed.init_process_group(backend=‘nccl’, init_method=‘tcp://localhost:1088’, rank=0, world_size=1)
However, no GPU works in train. And if I use nn.DataParallel, this problem is not existence.
DistributedDataParallel (DDP) is multi process training. For you case, you would get best performance with 8 DDP processes, where the i-th process calls:
torch.distributed.init_process_group(
backend=‘nccl’,
init_method=‘tcp://localhost:1088’,
rank=i,
world_size=8
)
Or, you could set env vars and use https://github.com/pytorch/pytorch/blob/master/torch/distributed/launch.py
Thanks for your reply. Now I can run my training program and GPU works, but nothing print in terminal. Why?
Can you share a code snippet? What do you expect to see in terminal?
Hello,
I am in a very similar situation where I have a single node and 8 GPUs. I used the following resource as a guideline for distributed parallel training: https://github.com/dnddnjs/pytorch-multigpu
I was able to run this example fine, but when I try to load the model, I get the following error:
Expected tensor for argument #1 ‘input’ to have the same device as tensor for argument #2 ‘weight’; but device 4 does not equal 0 (while checking arguments for cudnn_convolution)
Could this be a problem in how I am loading the training data?
Hi, it means that your input and model weight are not on the same device, just like your input on GPU-0 while your model weight on GPU-1. Note that both input and weight must be obtained by same device. I think it may be caused by the wrong load way. Can you show your loading code or give an example?
Thanks for the reply. I believe I found the error. The original code was written for a single GPU and unfortunately there were multiple places where cuda:0 was hardcoded.
However, I do have a followup question. From all the examples I have seen so far, the dataloader is associated with DistributedSampler: https://pytorch.org/docs/stable/_modules/torch/utils/data/distributed.html
In many cases the dataloader loads files in a directory. In the case of using DDP, the DistributedSampler would be used to allocate files for each GPU such that each GPU would get a unique distribution of samples from the total dataset (I am assuming that the total data items is integer divisible by the number of GPUs).
In my case I am loading 3D data and then take patches of this data, which serves as the training input of the network. So one data file corresponds to more than one training input.
What I do currently is that I load the data by loading the files in a folder. Then I use a custom sampler that loads the patch indices and has an iterator that passes patches when called. I feed this sampler to a Dataloader, where I pass in the whole data, the sampler, and batch size. This works fine for one GPU.
I am now moving on to converting my code to DDP. I could put the DistributedSampler after my custom sampler, but I worry about the idea of multiple GPUs accessing the same file (again the input is a patch and different patches can come from the same file). Am I correct to say that this would be a problem?
Another approach could be to put the DistributedSampler before my current sampler. But I am a bit unsure how to hook up this DistributedSampler to my existing code.
I suppose yet another method could be to bypass using torch.utils.data.distributed.DistributedSampler and perhaps instead have my initial Dataset have a getitem that distributes the files among the GPUs in a manner similar to the DistributedSampler, and then keep the rest of my hooks the same. Or alternatively, in the main loop I could have the logic for handling the distribution of files and pass this into the spawned process.
Would one approach be better than others? Or should I be using another approach altogether? Does the DDP work properly if the code does not use the DistributedSampler?
- Can you please define the terms: 1) node, 2) process in the context you are using them?
- If I want to train my model on 4 GPUs, do you call it 4 processes? or 1 process?
- Does
init_methodcorrespond to the address of my PC or to the GPU I’m accessing on a cluster? - In this tutorial, what were you referring to as machine?
- Can you please explain how you arrived at:
Hey @spabho
- Can you please define the terms: 1) node, 2) process in the context you are using them?
We usually use one node/machine/server to represent one physical computer which can be equipped with multiple GPUs.
One process is in the context of process/thread.
If I want to train my model on 4 GPUs, do you call it 4 processes? or 1 process?
In this case, using 4 processes with DDP should give you the best performance.
Does
init_methodcorrespond to the address of my PC or to the GPU I’m accessing on a cluster?
It corresponds to the address of your PC. It is giving some information for the 4 DDP processes to perform rendezvous.
In this tutorial, what were you referring to as machine?
Machines should always refer to node/server/machine/computer.
To be clear, there are three concepts involved in DDP training:
- Node/Machine/Server: a physical computer that can contain multiple GPUs. It can also talk to other node through network.
- GPU: just one GPU
- Process: Each process should run its own DDP instance. Usually Each DDP instance should exclusively operate on one GPU (if your model can fit in one GPU), and DDP instances will talk to each other through network.
This example might serve better as a starting point for DDP.
Hi @mrshenli,
I was looking at the tutorial you mentioned.
In the example, it says that
This example uses a
torch.nn.Linearas the local model, wraps it with DDP, and then runs one forward pass, one backward pass, and an optimizer step on the DDP model. After that, parameters on the local model will be updated, and all models on different processes should be exactly the same.
I’m just wondering what it means by local model, and what’s the difference between the local model and the models on different processes.
Thanks!
Hey @rzhang63, each process runs its own DDP model, which wraps the local model. DDP does not own any parameters (but it will create buffers/buckets for communication). So from the perspective of parameters, they are the same.
The reason for calling them local model vs DDP model is that, local model by itself does not perform communication across processes. DDP takes care of communication to make sure that different local models on difference processes are always in sync, as if all processes are operating on the same global module.
Hi @mrshenli,
Thank you for your reply. I was running the example code in the tutorial but I got the following error:
AttributeError: Can’t get attribute ‘demo_basic’ on <module ‘main’ (built-in)>
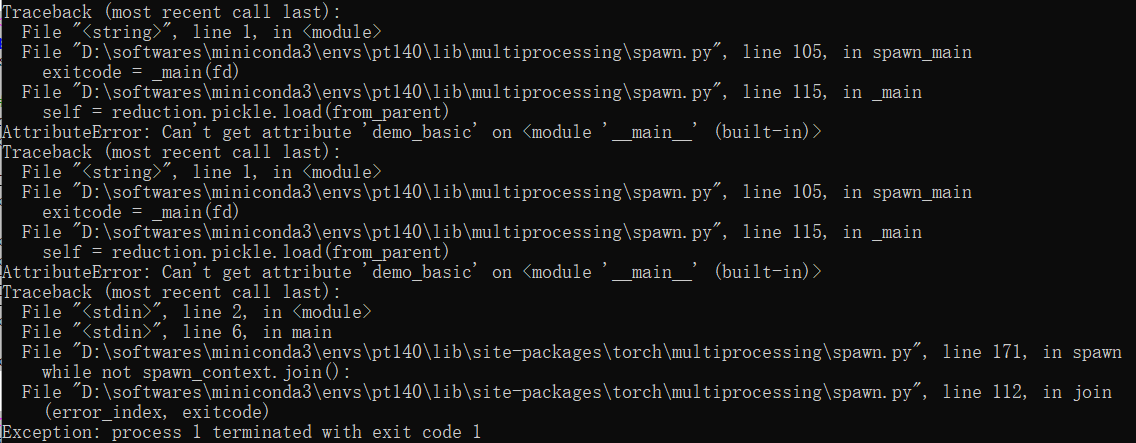
Do you know why this happened?
The link provided above points to the DDP example, but demo_basic is one function from Getting Started with Distributed Data Parallel — PyTorch Tutorials 2.1.1+cu121 documentation. Are you mixing these two?
The code I used is
import os
import tempfile
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
def demo_basic(rank, world_size):
print(f"Running basic DDP example on rank {rank}.")
setup(rank, world_size)
# create model and move it to GPU with id rank
model = nn.Linear(10, 10).to(rank)
ddp_model = DDP(model, device_ids=[rank])
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)
optimizer.zero_grad()
outputs = ddp_model(torch.randn(20, 10))
labels = torch.randn(20, 5).to(rank)
loss_fn(outputs, labels).backward()
optimizer.step()
cleanup()
def main():
world_size = 2
mp.spawn(demo_basic,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
main()
1 Like
Hey @rzhang63 sorry that I mis-read your log picture. Are you using Windows? Currently PT Distributed does not support windows yet. We have a poll here: https://github.com/pytorch/pytorch/issues/37068
If running on Linux, it should work with a minor fix.
Change
labels = torch.randn(20, 5).to(rank)
to
labels = torch.randn(20, 10).to(rank)
I just switched to Linux and changed the labels to labels = torch.randn(20, 10).to(rank), but I still got the following error:
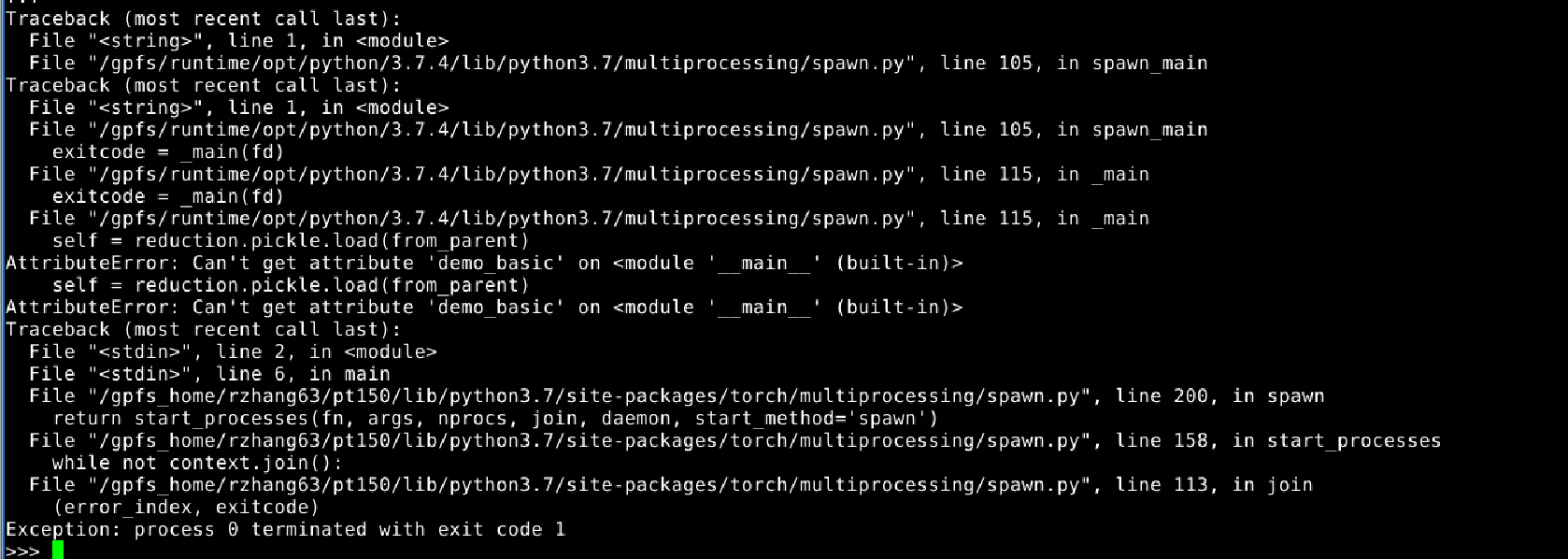
This seems to be a multiprocessing pickle issue. How did you launch it. Is it sth like python test.py from command line or through notebook?
And can you confirm you see the same error even if you remove all torch.distributed code? Say make demo_basic into the following and remove other functions?
def demo_basic(rank, world_size):
pass
This looks relevant to the error you are seeing: https://github.com/ipython/ipython/issues/10894