Is there any reason why skip connections would not provide the same benefits to fully connected layers as it does for convolutional?
I’ve read the ResNet paper and it says that the applications should extend to “non-vision” problems, so I decided to give it a try for a tabular data project I’m working on.
Try 1: My first try was to only skip connections when the input to a block matched the output size of the block (the block has depth - 1 number of layers with in_dim nodes plus a layer with out_dim nodes :
class ResBlock(nn.Module):
def __init__(self, depth, in_dim, out_dim, act='relu', act_first=True):
super().__init__()
self.residual = nn.Identity()
self.block = block(depth, in_dim, out_dim, act)
self.ada_pool = nn.AdaptiveAvgPool1d(out_dim)
self.activate = get_act(act)
self.apply_shortcut = (in_dim == out_dim)
def forward(self, x):
if self.apply_shortcut:
residual = self.residual(x)
x = self.block(x)
return self.activate(x + residual)
return self.activate(self.block(x))
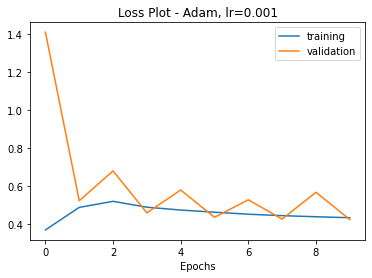
The accompanying loss curve:
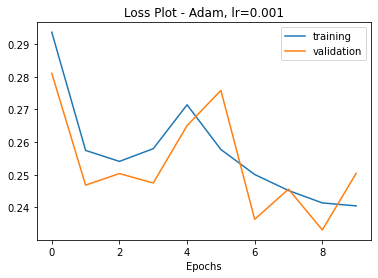
Try 2: I thought to myself “Great, it’s doing something!”, so then I decided to reset and go for 30 epochs. This training only made it 3-5 epochs and then the training and validation loss curves exploded by several orders of magnitude.
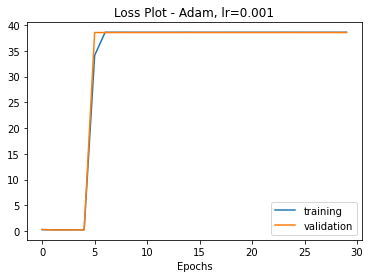
Try 3: Next, I decided to try to implement the paper’s idea of reducing the input size to match the output when they don’t match: y = F(x, {Wi}) + Mx. I chose average pooling in place of matrix M to accomplish this, and my loss curve became.
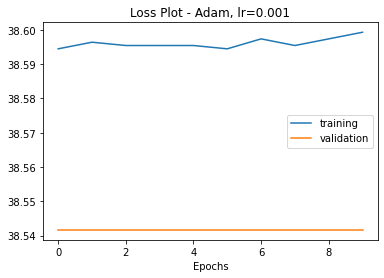
The only difference in my code is that I added average pooling so I could use shortcut connections when input and output sizes are different:
class ResBlock(nn.Module):
def __init__(self, depth, in_dim, out_dim, act='relu', act_first=True):
super().__init__()
self.residual = nn.Identity()
self.block = block(depth, in_dim, out_dim, act)
# squeeze/pad input to output size
self.ada_pool = nn.AdaptiveAvgPool1d(out_dim)
self.activate = get_act(act)
self.apply_pool = (in_dim != out_dim)
def forward(self, x):
# if in and out dims are different apply the padding/squeezing:
if self.apply_pool:
residual = self.ada_pool(self.residual(x).unsqueeze(0)).squeeze(0)
else: residual = self.residual(x)
x = self.block(x)
return self.activate(x + residual)
)
So, has anyone else tried something like this? This is my first try at something a little more advanced as far as building a network goes.
Any tips, tricks, ideas, theory, is appreciated!