Hi everyone,
I have created a few models using Deep Learning but mostly have worked with images. Unlike with audio, images can be cropped, resized, etc.
So, I was in the process of creating a Speech Recogniton model (for Spanish) as my thesis and I got to do these steps:
-
This is my dataset, the dataset are of different lengths.
-
I created spectrograms for each one of them with 128 features, and of course each one has different numbers of frames due to their duration variation.
-
I created a custom dataset where each data is spectrogram + label:
train_dataset = SpanishSpeechDataSet(csv_file='../input/spanish-single-speaker-speech-dataset/transcript.txt', root_dir='../input/spanish-single-speaker-speech-dataset/', data_type='train')
I did a test and show the spectrogram:
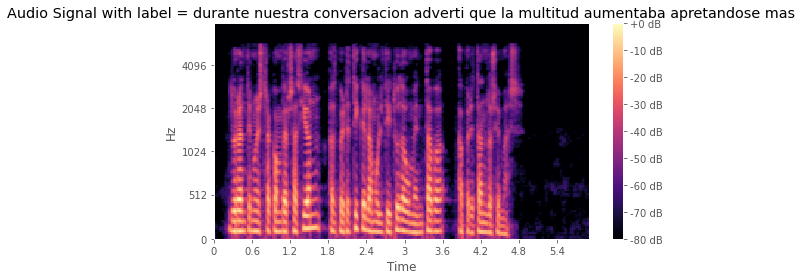
- I create a data processing function:
def data_processing(audio_data):
spectrograms = []
labels = []
input_lengths = []
label_lengths = []
for (spec,label) in audio_data:
#The spectrogram is in (128, 407) and (128, 355) for example but later on for padding the function expects (407, 128) and (355, 128). So we need to transpose the matrices.
spectrograms.append(torch.Tensor(spec.transpose()))
t = TextProcessing()
label = torch.Tensor(t.text2int(text=label))
labels.append(label)
input_lengths.append(spec.shape[0]//2)
label_lengths.append(len(label))
print(len(spectrograms))
spec_pad = torch.nn.utils.rnn.pad_sequence(spectrograms, batch_first=True).unsqueeze(1).transpose(2,3)
label_pad = torch.nn.utils.rnn.pad_sequence(labels, batch_first=True)
return spec_pad, label_pad, input_lengths, label_lengths
- DataLoader:
data_loader = DataLoader(dataset=train_dataset, batch_size=32,shuffle=True,collate_fn=lambda x: data_processing(x))
- Test the size of each:
it = iter(data_loader)
first = next(it)
second = next(it)
print(first[0].shape)
print(second[0].shape)
32
32
torch.Size([32, 1, 128, 594])
torch.Size([32, 1, 128, 558])
For each batch, the max size of the batch is different.
- Now, my question is if I want to pass these to a RNN, the input size would be 128 (number of features of the spectrogram) or would it be the frames (above case 594 or 558)? I am really confused!
Thanks.
BR,
Shweta.
