smeet
April 15, 2020, 3:17pm
1
Hi,
I am using Pytorch CTC loss function with Pytorch 1.2. I get a high accuracy after training the model using the native CTC loss implementation and the cuDNN deterministic flag set to False. However, the model accuracy is much poor when training using the native CTC loss implementation and the deterministic flag set to True. I read in a separate post that the cuDNN CTC loss implementation works better with the deterministic flag set to True. But I am unable to figure out how to force Pytorch CTC loss function to use the cuDNN implementation instead of the native implementation. I have also kept the torch.backends.cudnn.enabled flag as True.
Can someone please help me out?
Thanks.
Could you post a link to the post, where it’s described why the cudnn implementation should perform better than the native one?
smeet
April 16, 2020, 6:48am
3
Thanks for the prompt reply.
The link to the comment - https://github.com/pytorch/pytorch/issues/22234#issuecomment-511919416
I don’t have the issues listed in the comment but since the user claims to have got better performance with cuDNN CTC loss when the deterministic flag is set to True, I wanted to just give it a try.
Thanks for the link.autograd.profiler on the ctcloss call to check the kernel names to verify that the cudnn implementation is used.
I am trying to use the cuDNN implementation of CTCLoss. The docs note that you need to meet several conditions, I found them a bit unclear to someone less experienced so I’ll list them and elaborate on what I took them to mean.
targets must be in concatenated format (This means concatenated together as a 1D tensor with shape (sum(target_lengths)) as opposed to a 2D tensor with shape (N, S) where N is batch_size and S is the max target length (other targets are padded up to this length)all input_lengths must be T (question about this below)The blank token must be 0 target_lengths <= 256 (target_lengths is not a scalar but a rank-1 tensor with the length of each target in the batch. I assume this means no target can have length > 256)the integer arguments must be of dtype torch.int32 and not torch.long (integer arguments include targets, input_lengths and target_lengths. If you’re creating them with torch.tensor, pass dtype=torch.int32 as an argument.
Questions:
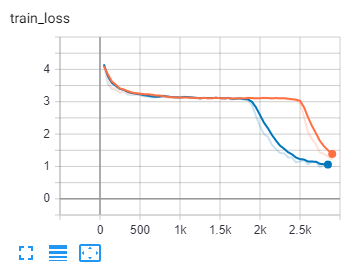
For the condition “all input_lengths must be T”, this means instead of passing the true input lengths, we just pass the length of the longest input. Doesn’t this make it impossible for CTCLoss to do masking? I changed my input_lengths from their true lengths to the length of the longest input in the batch (i.e. changed from [124, 92, 131, 118] to [131, 131, 131, 131) and my training suffered. Blue is using true input length, orange is using max input length.
How does CTCLoss choose whether to use the cuDNN implementation? nn.CTCLoss calls F.ctc_loss which calls torch.ctc_loss which is implemented in C++. I’m not sure where _use_cudnn_ctc_loss resides or what it does (I don’t know any C++)
Tensor ctc_loss(const Tensor& log_probs, const Tensor& targets, IntArrayRef input_lengths, IntArrayRef target_lengths, int64_t BLANK, int64_t reduction, bool zero_infinity) {
bool use_cudnn =
(log_probs.device().type() == at::kCUDA) &&
at::_use_cudnn_ctc_loss(
log_probs, targets, input_lengths, target_lengths, BLANK);
The docs say enabling cudnn (by setting torch.backends.cudnn.benchmark=True) is generally only faster in cases where input sizes don’t vary. In applications where we will use CTCLoss, they usually will vary. Why is it that the CTCLoss docs suggest cudnn as a good idea? What am I missing?
Thank you. Once I get cuDNN working I will report back with timing data to share how much of a speedup I was able to get.
I wasn’t quite sure how to do this but believe I figured it out. I wrapped my ctcloss call as follows
with torch.autograd.profiler.profile(use_cuda=True) as prof:
self.loss(output.transpose(0, 1), labels, input_lengths, label_lengths)
print(prof)
I also tried with use_cuda=False. Here are results from a single batch but I have no clue what to make of them.
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg CUDA total % CUDA total CUDA time avg Number of Calls Input Shapes
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------------------------------------
transpose 2.49% 89.784us 2.65% 95.700us 95.700us 1.02% 95.296us 95.296us 1 []
as_strided 0.16% 5.916us 0.16% 5.916us 5.916us 0.07% 6.112us 6.112us 1 []
ctc_loss 5.55% 200.390us 97.35% 3.515ms 3.515ms 37.75% 3.513ms 3.513ms 1 []
to 2.93% 105.918us 4.25% 153.553us 153.553us 1.65% 153.888us 153.888us 1 []
empty_strided 0.46% 16.663us 0.46% 16.663us 16.663us 0.17% 15.680us 15.680us 1 []
copy_ 0.86% 30.972us 0.86% 30.972us 30.972us 0.31% 29.216us 29.216us 1 []
contiguous 0.16% 5.751us 0.16% 5.751us 5.751us 0.05% 4.768us 4.768us 1 []
to 0.37% 13.377us 6.48% 234.179us 234.179us 2.50% 232.512us 232.512us 1 []
empty_strided 0.43% 15.453us 0.43% 15.453us 15.453us 0.17% 15.552us 15.552us 1 []
copy_ 2.64% 95.483us 5.69% 205.349us 205.349us 2.19% 204.032us 204.032us 1 []
empty_like 0.30% 10.769us 0.44% 15.732us 15.732us 0.16% 15.200us 15.200us 1 []
empty 0.14% 4.963us 0.14% 4.963us 4.963us 0.04% 3.456us 3.456us 1 []
expand_as 0.58% 20.971us 1.02% 36.836us 36.836us 0.39% 35.968us 35.968us 1 []
expand 0.29% 10.626us 0.44% 15.865us 15.865us 0.16% 15.072us 15.072us 1 []
as_strided 0.15% 5.239us 0.15% 5.239us 5.239us 0.06% 5.312us 5.312us 1 []
contiguous 0.13% 4.626us 0.13% 4.626us 4.626us 0.05% 4.512us 4.512us 1 []
copy_ 1.23% 44.279us 1.23% 44.279us 44.279us 0.47% 43.904us 43.904us 1 []
copy_ 0.23% 8.393us 0.23% 8.393us 8.393us 0.09% 8.352us 8.352us 1 []
contiguous 0.12% 4.220us 0.12% 4.220us 4.220us 0.04% 3.456us 3.456us 1 []
_use_cudnn_ctc_loss 0.37% 13.473us 0.37% 13.473us 13.473us 0.15% 13.824us 13.824us 1 []
to 0.37% 13.196us 12.79% 461.702us 461.702us 4.98% 463.168us 463.168us 1 []
empty_strided 0.62% 22.558us 0.62% 22.558us 22.558us 0.24% 22.560us 22.560us 1 []
copy_ 11.80% 425.948us 11.80% 425.948us 425.948us 4.58% 426.592us 426.592us 1 []
_ctc_loss 47.07% 1.700ms 54.50% 1.968ms 1.968ms 21.17% 1.970ms 1.970ms 1 []
size 0.13% 4.733us 0.13% 4.733us 4.733us 0.03% 3.200us 3.200us 1 []
size 0.23% 8.483us 0.23% 8.483us 8.483us 0.07% 6.912us 6.912us 1 []
stride 0.10% 3.616us 0.10% 3.616us 3.616us 0.04% 3.616us 3.616us 1 []
stride 0.09% 3.200us 0.09% 3.200us 3.200us 0.04% 3.904us 3.904us 1 []
empty 0.22% 7.967us 0.22% 7.967us 7.967us 0.08% 7.872us 7.872us 1 []
stride 0.09% 3.423us 0.09% 3.423us 3.423us 0.03% 3.168us 3.168us 1 []
stride 0.08% 2.815us 0.08% 2.815us 2.815us 0.03% 3.200us 3.200us 1 []
size 0.08% 2.947us 0.08% 2.947us 2.947us 0.03% 3.168us 3.168us 1 []
size 0.09% 3.168us 0.09% 3.168us 3.168us 0.05% 4.512us 4.512us 1 []
empty 0.13% 4.610us 0.13% 4.610us 4.610us 0.05% 4.320us 4.320us 1 []
to 0.46% 16.559us 1.82% 65.733us 65.733us 0.71% 65.664us 65.664us 1 []
empty_strided 0.36% 12.881us 0.36% 12.881us 12.881us 0.14% 12.800us 12.800us 1 []
copy_ 1.01% 36.293us 1.01% 36.293us 36.293us 0.39% 36.320us 36.320us 1 []
empty 0.14% 5.146us 0.14% 5.146us 5.146us 0.06% 5.184us 5.184us 1 []
to 0.38% 13.650us 1.23% 44.452us 44.452us 0.48% 44.544us 44.544us 1 []
empty_strided 0.24% 8.675us 0.24% 8.675us 8.675us 0.09% 8.672us 8.672us 1 []
copy_ 0.61% 22.127us 0.61% 22.127us 22.127us 0.24% 22.496us 22.496us 1 []
to 0.33% 11.906us 1.07% 38.530us 38.530us 10.73% 998.720us 998.720us 1 []
empty_strided 0.22% 7.977us 0.22% 7.977us 7.977us 0.08% 7.680us 7.680us 1 []
copy_ 0.52% 18.647us 0.52% 18.647us 18.647us 0.20% 18.720us 18.720us 1 []
size 0.16% 5.871us 0.16% 5.871us 5.871us 0.05% 5.024us 5.024us 1 []
empty 0.35% 12.695us 0.35% 12.695us 12.695us 0.13% 12.128us 12.128us 1 []
empty 0.37% 13.249us 0.37% 13.249us 13.249us 0.10% 9.248us 9.248us 1 []
stride 0.44% 15.907us 0.44% 15.907us 15.907us 0.17% 15.840us 15.840us 1 []
stride 0.11% 3.807us 0.11% 3.807us 3.807us 0.03% 3.168us 3.168us 1 []
stride 0.08% 3.006us 0.08% 3.006us 3.006us 0.24% 22.208us 22.208us 1 []
stride 0.15% 5.355us 0.15% 5.355us 5.355us 0.06% 5.536us 5.536us 1 []
stride 0.08% 3.025us 0.08% 3.025us 3.025us 0.03% 3.200us 3.200us 1 []
stride 0.09% 3.165us 0.09% 3.165us 3.165us 0.04% 3.424us 3.424us 1 []
size 0.10% 3.659us 0.10% 3.659us 3.659us 0.04% 3.712us 3.712us 1 []
empty 0.91% 32.938us 0.91% 32.938us 32.938us 0.34% 31.584us 31.584us 1 []
to 0.89% 32.273us 2.89% 104.484us 104.484us 1.13% 104.736us 104.736us 1 []
empty_strided 0.86% 30.962us 0.86% 30.962us 30.962us 0.33% 30.656us 30.656us 1 []
copy_ 1.14% 41.249us 1.14% 41.249us 41.249us 0.45% 42.240us 42.240us 1 []
clamp_min 0.79% 28.355us 2.91% 105.264us 105.264us 1.12% 104.032us 104.032us 1 []
empty 0.17% 6.280us 0.17% 6.280us 6.280us 0.07% 6.336us 6.336us 1 []
clamp_min_out 1.58% 57.135us 1.96% 70.629us 70.629us 0.77% 71.872us 71.872us 1 []
is_complex 0.14% 5.133us 0.14% 5.133us 5.133us 0.05% 4.864us 4.864us 1 []
resize_ 0.23% 8.361us 0.23% 8.361us 8.361us 0.08% 7.712us 7.712us 1 []
div 2.89% 104.223us 3.06% 110.646us 110.646us 1.19% 110.272us 110.272us 1 []
empty 0.18% 6.423us 0.18% 6.423us 6.423us 0.06% 5.120us 5.120us 1 []
mean 2.63% 95.114us 3.34% 120.721us 120.721us 1.30% 120.896us 120.896us 1 []
empty 0.21% 7.698us 0.21% 7.698us 7.698us 0.07% 6.208us 6.208us 1 []
as_strided 0.50% 17.909us 0.50% 17.909us 17.909us 0.10% 9.504us 9.504us 1 []
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------------------------------------
Self CPU time total: 3.611ms
CUDA time total: 9.305ms
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------------------------------------
Name Self CPU total % Self CPU total CPU total % CPU total CPU time avg Number of Calls Input Shapes
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------------------------------------
transpose 2.69% 71.228us 2.83% 74.813us 74.813us 1 []
as_strided 0.14% 3.585us 0.14% 3.585us 3.585us 1 []
ctc_loss 7.54% 199.357us 97.17% 2.569ms 2.569ms 1 []
to 0.83% 21.988us 1.82% 48.160us 48.160us 1 []
empty_strided 0.34% 8.955us 0.34% 8.955us 8.955us 1 []
copy_ 0.65% 17.217us 0.65% 17.217us 17.217us 1 []
contiguous 0.06% 1.582us 0.06% 1.582us 1.582us 1 []
to 0.13% 3.550us 4.72% 124.691us 124.691us 1 []
empty_strided 0.15% 3.899us 0.15% 3.899us 3.899us 1 []
copy_ 1.30% 34.434us 4.43% 117.242us 117.242us 1 []
empty_like 0.22% 5.833us 0.29% 7.693us 7.693us 1 []
empty 0.07% 1.860us 0.07% 1.860us 1.860us 1 []
expand_as 0.43% 11.263us 0.67% 17.590us 17.590us 1 []
expand 0.16% 4.158us 0.24% 6.327us 6.327us 1 []
as_strided 0.08% 2.169us 0.08% 2.169us 2.169us 1 []
contiguous 0.11% 2.921us 0.11% 2.921us 2.921us 1 []
copy_ 1.88% 49.606us 1.88% 49.606us 49.606us 1 []
copy_ 0.19% 4.998us 0.19% 4.998us 4.998us 1 []
contiguous 0.04% 1.070us 0.04% 1.070us 1.070us 1 []
_use_cudnn_ctc_loss 0.28% 7.475us 0.28% 7.475us 7.475us 1 []
to 0.23% 6.097us 9.79% 258.968us 258.968us 1 []
empty_strided 0.58% 15.438us 0.58% 15.438us 15.438us 1 []
copy_ 8.98% 237.433us 8.98% 237.433us 237.433us 1 []
_ctc_loss 8.69% 229.677us 14.88% 393.415us 393.415us 1 []
size 0.04% 1.144us 0.04% 1.144us 1.144us 1 []
size 0.01% 0.357us 0.01% 0.357us 0.357us 1 []
stride 0.03% 0.779us 0.03% 0.779us 0.779us 1 []
stride 0.02% 0.399us 0.02% 0.399us 0.399us 1 []
empty 0.19% 4.969us 0.19% 4.969us 4.969us 1 []
stride 0.01% 0.340us 0.01% 0.340us 0.340us 1 []
stride 0.01% 0.329us 0.01% 0.329us 0.329us 1 []
size 0.02% 0.459us 0.02% 0.459us 0.459us 1 []
size 0.01% 0.356us 0.01% 0.356us 0.356us 1 []
empty 0.06% 1.577us 0.06% 1.577us 1.577us 1 []
to 0.30% 7.838us 2.99% 79.032us 79.032us 1 []
empty_strided 1.16% 30.741us 1.16% 30.741us 30.741us 1 []
copy_ 1.53% 40.453us 1.53% 40.453us 40.453us 1 []
empty 0.09% 2.455us 0.09% 2.455us 2.455us 1 []
to 0.16% 4.242us 1.24% 32.838us 32.838us 1 []
empty_strided 0.24% 6.368us 0.24% 6.368us 6.368us 1 []
copy_ 0.84% 22.228us 0.84% 22.228us 22.228us 1 []
to 0.18% 4.814us 1.08% 28.688us 28.688us 1 []
empty_strided 0.18% 4.860us 0.18% 4.860us 4.860us 1 []
copy_ 0.72% 19.014us 0.72% 19.014us 19.014us 1 []
size 0.02% 0.587us 0.02% 0.587us 0.587us 1 []
empty 0.16% 4.245us 0.16% 4.245us 4.245us 1 []
empty 0.11% 2.879us 0.11% 2.879us 2.879us 1 []
stride 0.02% 0.497us 0.02% 0.497us 0.497us 1 []
stride 0.01% 0.273us 0.01% 0.273us 0.273us 1 []
stride 0.01% 0.300us 0.01% 0.300us 0.300us 1 []
stride 0.01% 0.283us 0.01% 0.283us 0.283us 1 []
stride 0.01% 0.309us 0.01% 0.309us 0.309us 1 []
stride 0.01% 0.292us 0.01% 0.292us 0.292us 1 []
size 0.01% 0.351us 0.01% 0.351us 0.351us 1 []
empty 0.22% 5.794us 0.22% 5.794us 5.794us 1 []
to 0.18% 4.859us 4.97% 131.370us 131.370us 1 []
empty_strided 0.35% 9.326us 0.35% 9.326us 9.326us 1 []
copy_ 4.43% 117.185us 4.43% 117.185us 117.185us 1 []
clamp_min 0.62% 16.405us 40.46% 1.070ms 1.070ms 1 []
empty 0.14% 3.831us 0.14% 3.831us 3.831us 1 []
clamp_min_out 39.34% 1.040ms 39.70% 1.050ms 1.050ms 1 []
is_complex 0.06% 1.470us 0.06% 1.470us 1.470us 1 []
resize_ 0.30% 8.027us 0.30% 8.027us 8.027us 1 []
div 5.41% 143.063us 5.80% 153.296us 153.296us 1 []
empty 0.39% 10.233us 0.39% 10.233us 10.233us 1 []
mean 6.18% 163.432us 6.59% 174.188us 174.188us 1 []
empty 0.33% 8.614us 0.33% 8.614us 8.614us 1 []
as_strided 0.08% 2.142us 0.08% 2.142us 2.142us 1 []
----------------------- --------------- --------------- --------------- --------------- --------------- --------------- ---------------------------------------------
Self CPU time total: 2.644ms