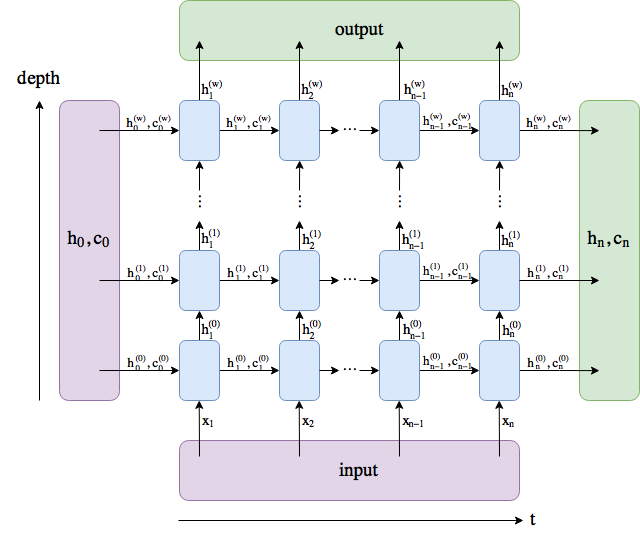
Your out is the output in this image and contains the hidden states for each timestamp. If you have an LSTM with multiple layers, they will be the hidden states of last layer; and it gets a tad more complicated in case of a bidirectional LSTM. This is why the default shape of output is (seq_len, batch, num_directions * hidden_size)
Your hidden is the tuple (h_n, c_n) in the image. For further processing, you use h_n which contains the last hidden state w.r.t. to your sequence, i.e., the hidden state after the last time step. If you use multi layers, it will contain the last hidden states for all layers. Again, Bi-LSTM adds a little complexity. The default shape of h_n – (num_layers * num_directions, batch, hidden_size) – reflects this.
There are no hard rules when to use output or h_n. It depends on your task and your network model, i.e., what kind of information you want to consider. For example, for basic classification, the default method is to use the last hidden state h_n (technically, h_n[-1] to get the last hidden state to the last layer). But you can also use output and sum or average the hidden states of all time steps.
Hi @vdw . What would be the purpose of using the sum or average of the hidden states? Does it capture a better representation of the sequence somehow? I’m trying to figure out what to do with my implementation of my LSTM and can’t really find any theory discussing what to feed into the fully connected layer or why. Is there any method to the madness?