Hi,
I’m new to Pytorch. I have trained a simple neural network with a pooling layer and then a convolutional layer to recognize images. I am using SpykeTorch, an open-source simulation framework based on PyTorch, to create my layers:
import SpykeTorch.snn as snn
pool = snn.Pooling(kernel_size = 3, stride = 2)
conv = snn.Convolution(in_channels=4, out_channels=20, kernel_size=30)
I want to visualize the learned convolutional filters that are passed over each input image. The snn.Convolution class is based on Pytorch’s nn.Module, but I’m not able to figure out how to visualize the filters. I have read past forum posts on this topic, saying to do weight = conv1.weight.data.numpy(), but my output tensor is of size [20, 4, 30, 30]. From what I understand, the 20 is the number of final feature maps in the layer after the filters are passed over the 4 input channels, not the number of filters, so I’m not sure how this approach works?
Side note: Spyketorch simulates Convolutional Spiking Neural Networks, so the input and output of each layer is in the form of a spike wave tensor of dimensions [time_step_max, feature_number, width, height] (time dimension replaces batch size).
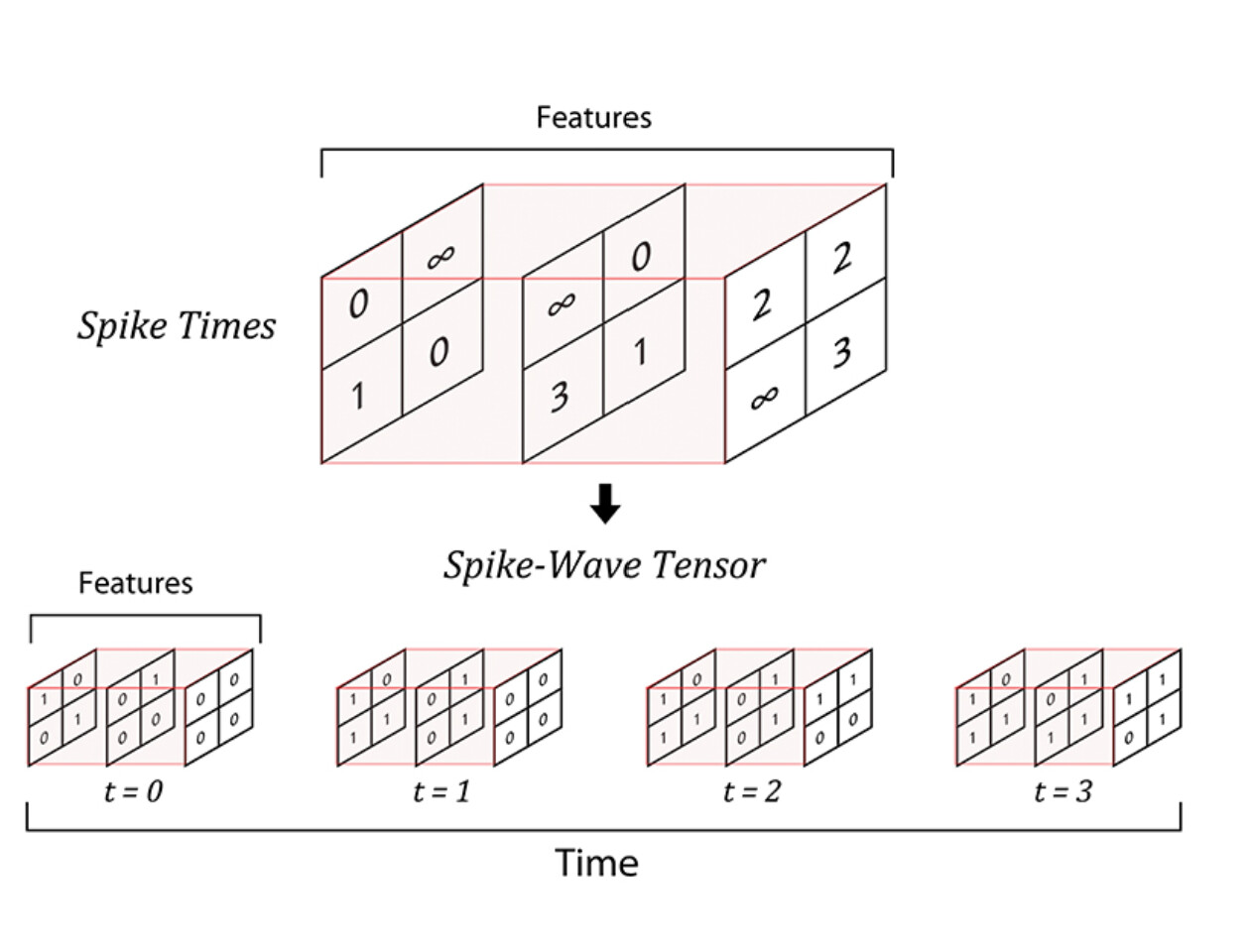
This is what a forward pass of the network looks like:
for iter in range(30):
print(‘\rIteration:’, iter, end=“”)
for data,_ in train_loader:
for x in data:
x = pool(x)
p = conv(x)
o, p = sf.fire(p, 20, return_thresholded_potentials=True)
winners = sf.get_k_winners(p, kwta=1, inhibition_radius=0, spikes=o)
stdp(x, p, o, winners)
print()
print(“Unsupervised Training is Done.”)
Thank you in advance!