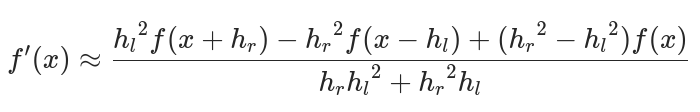I am reading the docs for the torch.gradient function but I can’t understand how the gradient is calculated. Specifically, for the first example where gradient for f(x) = x**2 is approximated, how we can compute a gradient without knowing the function value at f(x+hl) and f(x+hr)? The docs say that the function derivative is approximated with the following formula:
Still I don’t get how the derivative is calculated. In your examples basically we have the functions y=x and y=0.5*x. Lets focus on the first example where the first coordinate is 1 and the value is 1. I can’t understand how from just these values torch.gradient is able to calculate the derivative which equals 1.