I have a network that includes one encoder and two decoders. The two decoders share the same encoder. The paper said
SO and CO branches - We take the downsampling branch of a U-Net as it is, however we split the upsampling branch into two halves, one to obtain the Region of Interest and the other for Complementary aka non region of interest. Losses here are negative dice for ROI and positive dice for Non-ROI region.
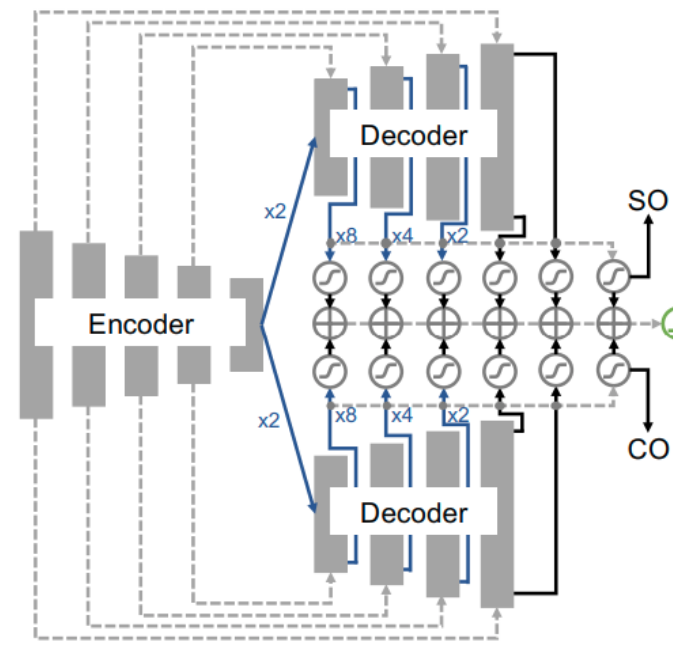
Assume that the encoder provides the feature likes
encoder_feature =[ f1, f2, f3, f4, f5]
So, both decoder_SO and decoder_CO use encoder features to update the weights. Which one is correct?
decoder_SO = [ up_sample(f1), up_sample(f2), up_sample(f3), up_sample(f4), up_sample(f5) ]
decoder_CO = [ up_sample(f1), up_sample(f2), up_sample(f3), up_sample(f4), up_sample(f5) ]
Or using detach()
decoder_SO = [ up_sample(f1), up_sample(f2), up_sample(f3), up_sample(f4), up_sample(f5) ]
decoder_CO = [ up_sample(f1.detach()), up_sample(f2.detach()), up_sample(f3.detach()), up_sample(f4.detach()), up_sample(f5.detach()) ]