Dear eveyone: sorry to disturb us. When I follow the HuBert tutorials to extract audio features.
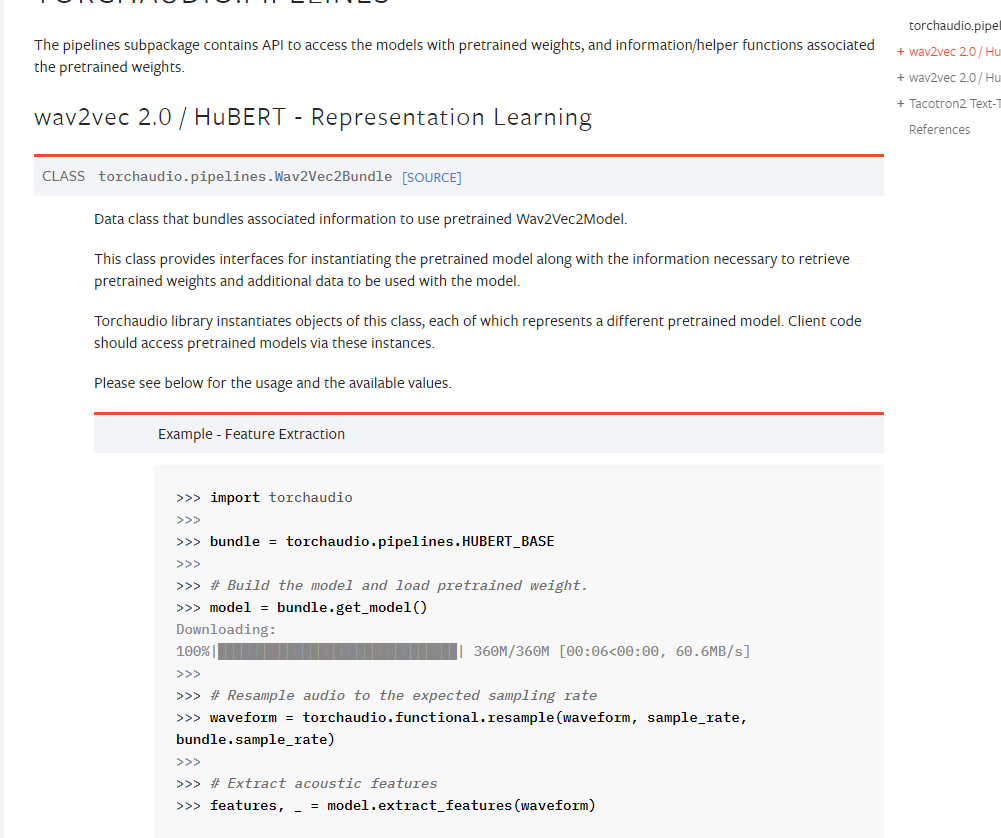
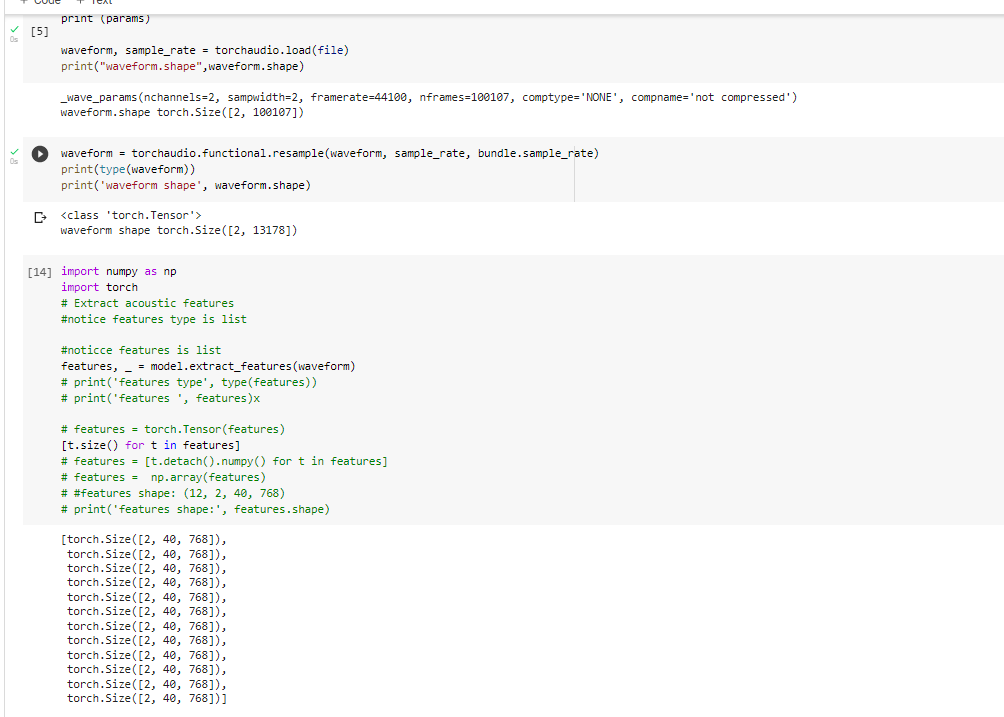
Finally, features, _ = model.extract_features(waveform).
features are saved in the form of a list. There are a total of 12 elements in the list, each element is in the form of tensor, and the shape is [2, 40, 768]. So when you finally use the feature, do you stack the 12 tensor directly and shape it into [12, 2, 40, 768]. Is there a theoretical problem with doing this?Could you please give me some suggestions?
Thanks, best wishes.