Hi,
I am currently trying to refactor some old TensorFlow code (1.15) into PyTorch (1.7.1). The code takes an image and upscales it using bilinear interpolation. To make sure both functions return the same results, I saved them as npy file and wrote a script to compare them. (See code snippets below)
Until a resize factor of ~5 they are equal to 4 decimal after they start introducing numerical differences.
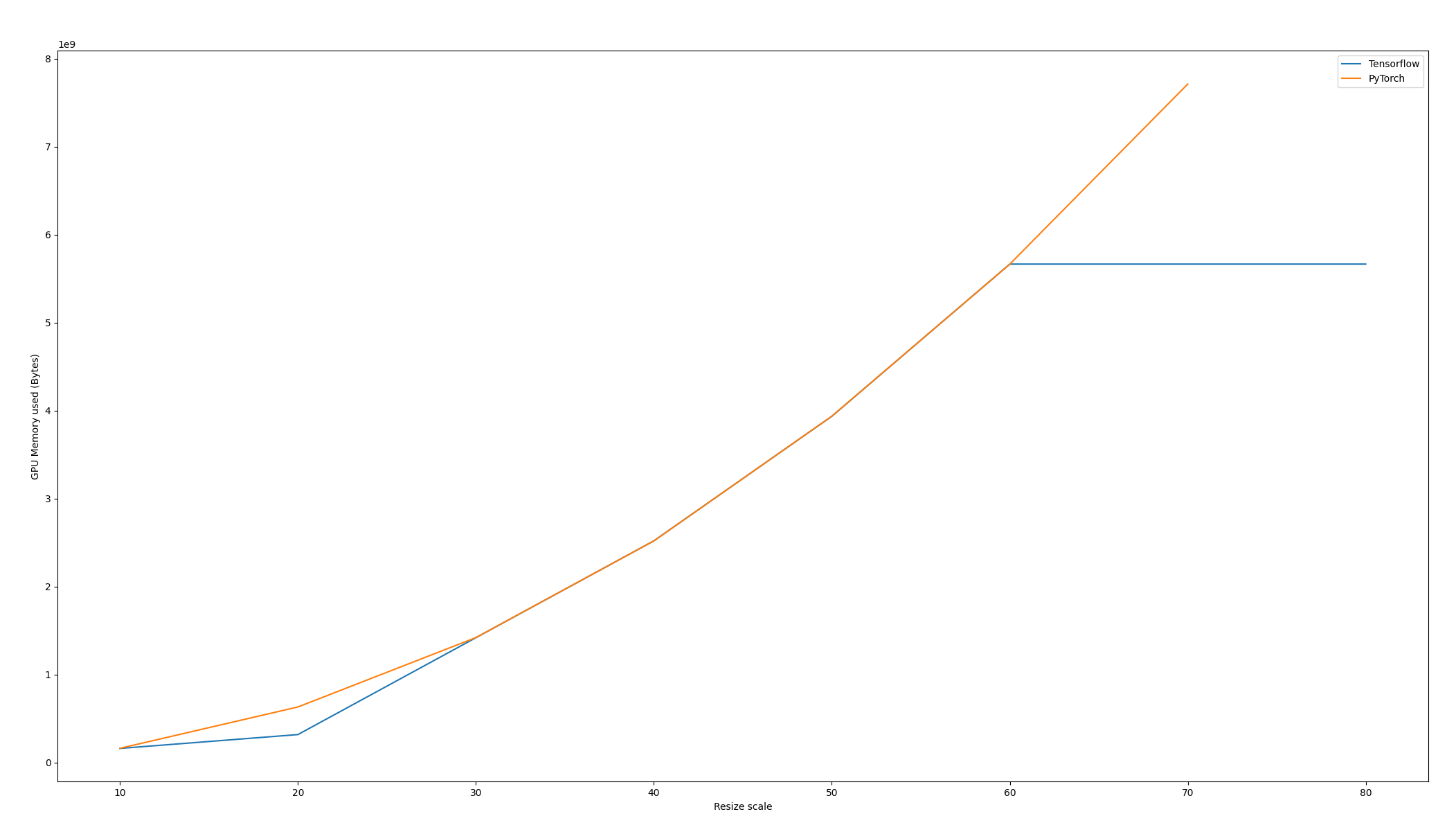
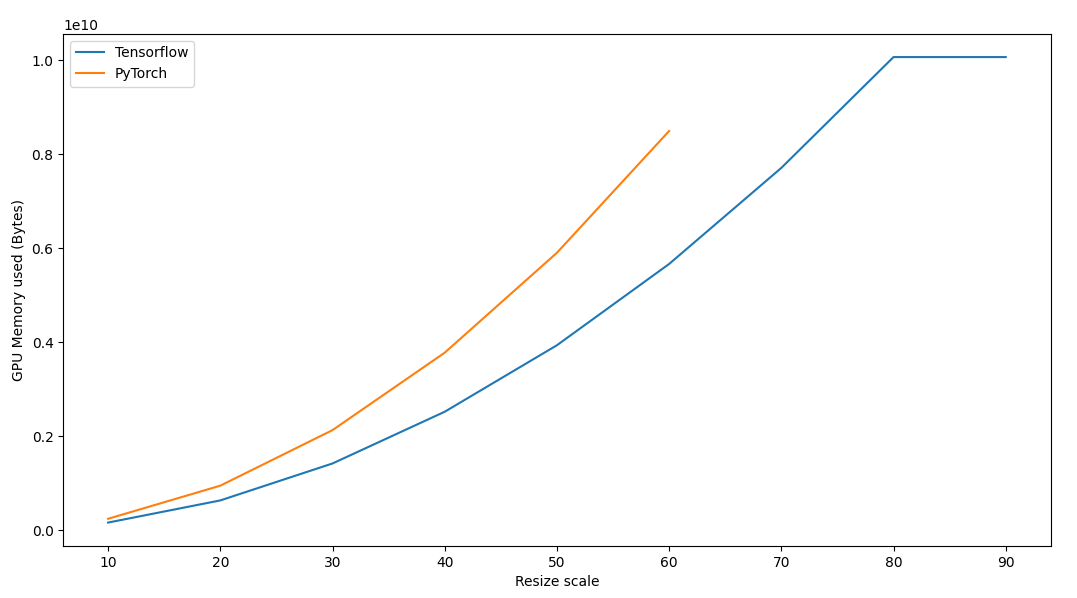
However, the memory used is VERY different as you can see in this image. Also, PyTorch crashes after a resize scale of 60.
Can anyone tell me why this is happening or how to fix it?
Torch script:
import torch
import torch.nn.functional as F
import sys
from math import log2
import numpy as np
from PIL import Image
_suffixes = ["bytes", "KiB", "MiB", "GiB", "TiB", "PiB", "EiB", "ZiB", "YiB"]
def file_size(size):
order = int(log2(size) / 10) if size else 0
return "{:.4g} {}".format(size / (1 << (order * 10)), _suffixes[order])
def main(resizescale=4):
device = torch.device("cuda")
w = 256
h = 256
print(f"Creating image")
np_image = np.array(Image.open("test.png")).transpose((2, 0, 1))[None, ...]
image = torch.tensor(np_image, device=device, dtype=torch.float32)
image.requires_grad = True
print(f"Resizing with resize scale: {resizescale}")
resized = F.interpolate(
image,
size=[int(resizescale * h), int(resizescale * w)],
mode="bilinear",
align_corners=True,
)
print(f"current size: {resized.shape}")
sum = resized.sum()
sum.backward()
np.save("torch_image.npy", resized.detach().cpu().numpy())
np.save("torch_grad.npy", image.grad.detach().cpu().numpy())
print(f"current mem: {file_size(torch.cuda.max_memory_allocated(0))}")
if __name__ == "__main__":
main(float(sys.argv[1]))
Tensorflow script:
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
import tensorflow as tf
import sys
from math import log2
import numpy as np
from PIL import Image
_suffixes = ["bytes", "KiB", "MiB", "GiB", "TiB", "PiB", "EiB", "ZiB", "YiB"]
def file_size(size):
order = int(log2(size) / 10) if size else 0
return "{:.4g} {}".format(size / (1 << (order * 10)), _suffixes[order])
def main(resizescale=4):
# create an image tensor
w = 256
h = 256
print(f"Creating image")
np_image = np.array(Image.open("test.png"))[None, ...]
image = tf.placeholder(tf.dtypes.float32, shape=(1, h, w, 3))
resized = [int(resizescale * h), int(resizescale * w)]
print(f"current size: {resized}")
size = tf.constant(resized, dtype=tf.int32)
d = tf.compat.v1.image.resize(
image, size, method=tf.image.ResizeMethod.BILINEAR, align_corners=True
) # upsample w/ BICUBIC -> artifacts
sum = tf.reduce_sum(d)
g = tf.gradients(sum, [image])
with tf.compat.v1.Session() as sess:
cur_image, gradient = sess.run([d, g], feed_dict={image: np_image})
np.save("tf_image.npy", cur_image)
np.save("tf_grad.npy", gradient)
max_mem = sess.run(tf.contrib.memory_stats.MaxBytesInUse())
mem = sess.run(tf.contrib.memory_stats.BytesInUse())
print(f"mem: {file_size(mem)}")
print(f"max_mem: {file_size(max_mem)}")
if __name__ == "__main__":
main(float(sys.argv[1]))
Compare script:
import numpy as np
torch_image = np.load("torch_image.npy")
tf_image = np.load("tf_image.npy")
torch_image_reshape = torch_image.transpose((0, 2, 3, 1))
tf_grad = np.load("tf_grad.npy")[0]
torch_grad = np.load("torch_grad.npy")
torch_grad_reshape = torch_grad.transpose((0, 2, 3, 1))
print(np.mean(np.abs(tf_image - torch_image_reshape)))
np.testing.assert_array_almost_equal(tf_image, torch_image_reshape, decimal=4)
np.testing.assert_array_almost_equal(tf_grad, torch_grad_reshape, decimal=6)