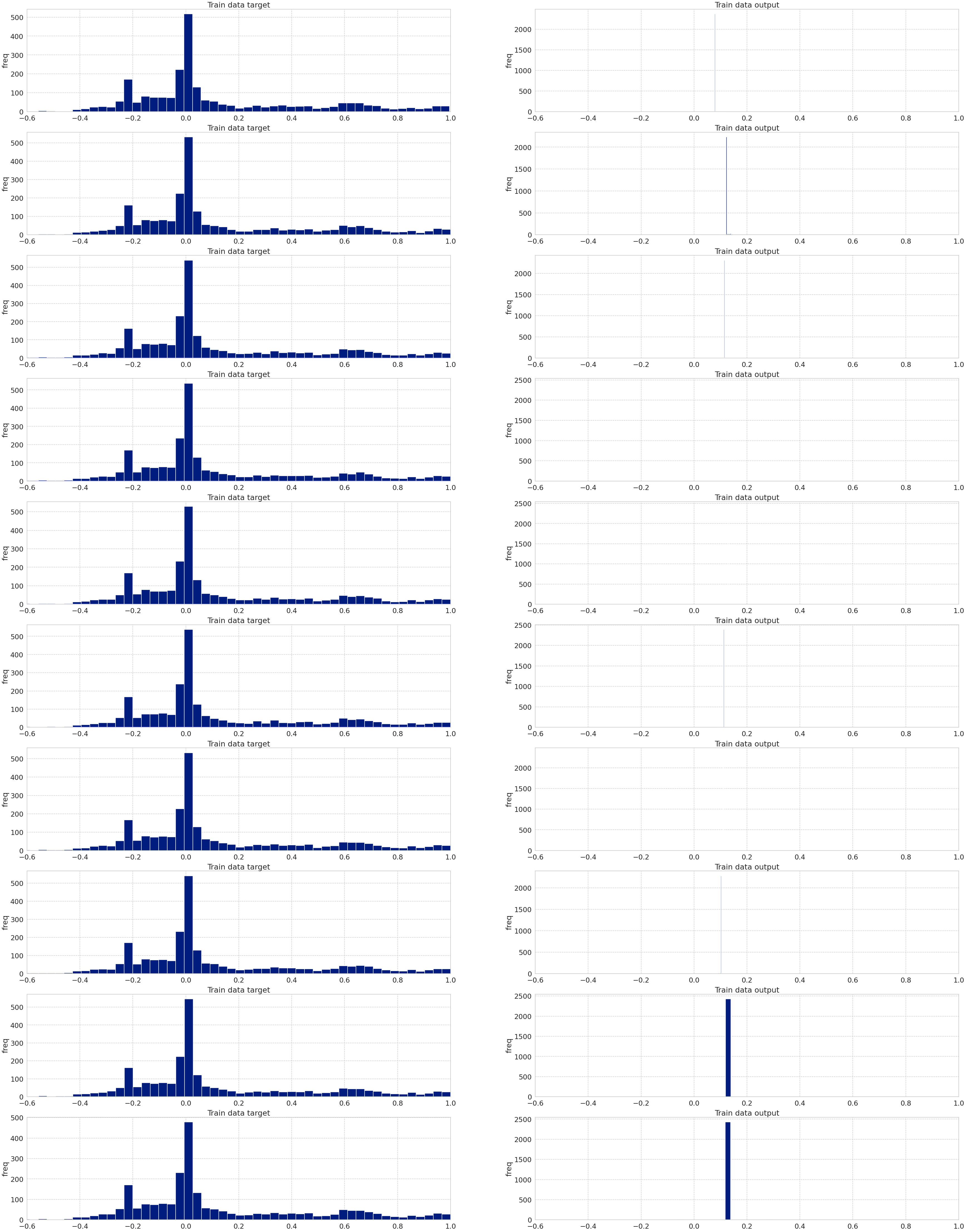
I am currently building a CNN Regression model.
My model architecture is like the following:
class RegressionNet(torch.nn.Module):
def __init__(self, input_size=None, output_size=None):
super(RegressionNet, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, 3)
self.conv2 = torch.nn.Conv2d(16, 32, 3)
self.pool1 = torch.nn.MaxPool2d(2, 2)
self.pool2 = torch.nn.MaxPool2d(2, 2)
self.input_size = input_size
self.neurons = self.linear_input_neurons()
self.fc1 = torch.nn.Linear(self.linear_input_neurons(), 1024)
self.fc2 = torch.nn.Linear(1024, 1024)
self.fc3 = torch.nn.Linear(1024, output_size)
def forward(self, x):
x = torch.nn.functional.relu(self.conv1(x))
x = self.pool1(x)
x = torch.nn.functional.relu(self.conv2(x))
x = self.pool2(x)
x = x.view(-1, self.neurons)
x = torch.nn.functional.relu(self.fc1(x))
x = self.fc3(x)
return x
# here we apply convolution operations before linear layer, and it returns the 4-dimensional size tensor.
def size_after_relu(self, x):
x = self.pool1(torch.nn.functional.relu(self.conv1(x)))
x = self.pool2(torch.nn.functional.relu(self.conv2(x)))
return x.size()
# after obtaining the size in above method, we call it and multiply all elements of the returned size.
def linear_input_neurons(self):
size = self.size_after_relu(torch.rand(1, self.input_size[1], self.input_size[2], self.input_size[3]))
m = 1
for i in size[1:]:
m *= i
return int(m)
My Optimizer and Loss function:
optimizer = torch.optim.Adam(net.parameters(), lr=0.01)
criterion = torch.nn.MSELoss()
Here comes the problem. The training loss in the first epoch is always so huge compared to the valid loss. Is this considered normal as I am using MSE or is there something wrong with my model architecture?
Training for fold 1...
#epoch:0 train loss: 27131208.35759782 valid loss: 0.46788424253463745
#epoch:1 train loss: 1.5370321702212095 valid loss: 0.1842787116765976
#epoch:2 train loss: 0.778756458312273 valid loss: 0.0377110888560613
#epoch:3 train loss: 0.5970308864489198 valid loss: 0.15821123123168945
#epoch:4 train loss: 0.4514023452997208 valid loss: 0.04207026958465576
#epoch:5 train loss: 0.377790588264664 valid loss: 0.059929460287094116
#epoch:6 train loss: 0.32543586088078363 valid loss: 0.06739359242575509
#epoch:7 train loss: 0.2817680644802749 valid loss: 0.051879264414310455
#epoch:8 train loss: 0.2456693003575007 valid loss: 0.028462330500284832
#epoch:9 train loss: 0.22231043577194215 valid loss: 0.03528459072113037
#epoch:10 train loss: 0.20242950726639142 valid loss: 0.03365590355613015
#epoch:11 train loss: 0.18334306310862303 valid loss: 0.024180124203364056
#epoch:12 train loss: 0.16663667731560194 valid loss: 0.010484489110799937
#epoch:13 train loss: 0.156691970835839 valid loss: 0.020529921565737044
#epoch:14 train loss: 0.14648786981900533 valid loss: 0.021238839626312254
#epoch:15 train loss: 0.13558033714070916 valid loss: 0.011424148455262184