Hello! I’m relatively new to Pytorch and I am trying to write a custom Rasa intent classifier (essentially a text classifier) with a pre-trained Huggingface model (in my case, that model is albert-base-v2). Unfortunately, I am absolutely stuck at a Pytorch-specific issue that I’ve read about for hours on end and I don’t get where the actual problem is. I’ve checked the input and output sizes and even tried some tricks (torch.unsqueeze(), one-hot encoding the output labels etc.) and none of those worked.
Here is the code:
from typing import Text, Dict, List, Type, Any, Optional
import os, logging
import numpy as np
import torch
from torch.utils.data import Dataset
from joblib import dump, load
from transformers import AutoTokenizer
from transformers import AutoModelForSequenceClassification
from transformers import AutoConfig
from transformers import Trainer, TrainingArguments
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import precision_recall_fscore_support, accuracy_score
from rasa.nlu.classifiers.classifier import IntentClassifier
from rasa.engine.recipes.default_recipe import DefaultV1Recipe
from rasa.engine.graph import ExecutionContext, GraphComponent
from rasa.engine.storage.resource import Resource
from rasa.shared.nlu.training_data.training_data import TrainingData
from rasa.shared.nlu.training_data.message import Message
from rasa.engine.storage.storage import ModelStorage
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
class CustomDataset(Dataset):
"""
Dataset for training the model.
"""
def __init__(self, encodings, labels):
# print("CustomDataset --> encodings: {}".format(encodings))
# print("CustomDataset --> labels: {}".format(labels))
self.encodings = encodings
# self.labels = torch.nn.functional.one_hot(torch.tensor(labels))
self.labels = labels
print("CustomDataset --> labels tensor size: {}".format(torch.tensor(labels).size()))
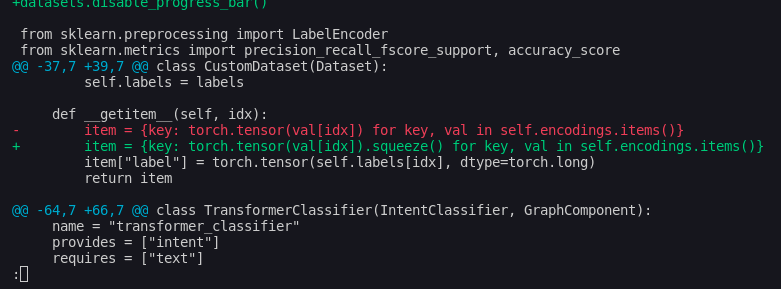
def __getitem__(self, idx):
# print("CustomDataset --> self.encodings.items(): {}".format(self.encodings.items()))
item = {key: torch.tensor(val[idx]).squeeze() for key, val in self.encodings.items()}
item["label"] = torch.tensor(self.labels[idx], dtype=torch.long)
print("CustomDataset --> __getitem__ -> input_ids: {}".format(item['input_ids']))
print("CustomDataset --> __getitem__ -> label: {}".format(item['label']))
return item
def __len__(self):
return len(self.labels)
def compute_metrics(pred):
"""
Helper function to compute aggregated metrics from predictions.
"""
print("compute_metrics --> pred: {}".format(pred))
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
precision, recall, f1, _ = precision_recall_fscore_support(
labels, preds, average="weighted"
)
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
@DefaultV1Recipe.register(
DefaultV1Recipe.ComponentType.INTENT_CLASSIFIER, is_trainable=True
)
class TransformerClassifier(IntentClassifier, GraphComponent):
name = "transformer_classifier"
provides = ["intent"]
requires = ["text"]
model_name = "albert-base-v2"
@classmethod
def required_components(cls) -> List[Type]:
return []
@staticmethod
def get_default_config() -> Dict[Text, Any]:
return {
'epochs': 15,
'batch_size': 24,
'warmup_steps': 500,
'weight_decay': 0.01,
'learning_rate': 2e-5,
'scheduler_type': 'constant',
'max_length': 64
}
@staticmethod
def supported_languages() -> Optional[List[Text]]:
"""Determines which languages this component can work with.
Returns: A list of supported languages, or `None` to signify all are supported.
"""
return None
@classmethod
def create(
cls,
config: Dict[Text, Any],
model_storage: ModelStorage,
resource: Resource,
execution_context: ExecutionContext,
) -> GraphComponent:
return cls(config, execution_context.node_name, model_storage, resource)
def __init__(
self,
config: Dict[Text, Any],
name: Text,
model_storage: ModelStorage,
resource: Resource,
) -> None:
self.name = name
self.label2id = {}
self.id2label = {}
self._define_model()
# We need to use these later when saving the trained component.
self._model_storage = model_storage
self._resource = resource
def _define_model(self):
"""
Loads the pretrained model and the configuration after the data has been preprocessed.
"""
print("=== Model name ===> {}".format(self.model_name))
self.config = AutoConfig.from_pretrained(self.model_name)
self.config.id2label = self.id2label
self.config.label2id = self.label2id
self.config.num_labels = len(self.id2label)
self.model = AutoModelForSequenceClassification.from_pretrained(
self.model_name, config=self.config
)
def _compute_label_mapping(self, labels):
"""
Maps the labels to integers and stores them in the class attributes.
"""
print("compute_label_mappings --> labels: {}".format(labels))
label_encoder = LabelEncoder()
integer_encoded = label_encoder.fit_transform(labels)
print("compute_label_mappings --> integer_encoded: {}".format(integer_encoded))
self.label2id = {}
self.id2label = {}
for label in np.unique(labels):
self.label2id[label] = int(label_encoder.transform([label])[0])
for i in integer_encoded:
self.id2label[int(i)] = label_encoder.inverse_transform([i])[0]
print("compute_label_mappings --> label2id: {}".format(self.label2id))
print("compute_label_mappings --> id2label: {}".format(self.id2label))
def _preprocess_data(self, data, params):
"""
Preprocesses the data to be used for training.
"""
documents = []
labels = []
for message in data.training_examples:
if "text" in message.data:
documents.append(message.data["text"])
labels.append(message.data["intent"])
self._compute_label_mapping(labels)
targets = [self.label2id[label] for label in labels]
encodings = self.tokenizer(
documents,
padding="max_length",
max_length=params.get("max_length", 64),
truncation=True,
)
dataset = CustomDataset(encodings, targets)
return dataset
def train(self, training_data: TrainingData) -> TrainingData:
"""
Preprocesses the data, loads the model, configures the training and trains the model.
"""
self.tokenizer = AutoTokenizer.from_pretrained(self.model_name)
component_config = self.get_default_config()
dataset = self._preprocess_data(training_data, component_config)
print("Dataset:", dataset)
print("Inputs: {}".format(dataset.encodings))
print("Targets: {}".format(dataset.labels))
print("Inputs size: {}".format(len(dataset.encodings['input_ids'])))
print("Targets size: {}".format(len(dataset.labels)))
# self._define_model()
training_args = TrainingArguments(
output_dir="./custom_model",
num_train_epochs=component_config.get("epochs", 15),
evaluation_strategy="no",
per_device_train_batch_size=component_config.get("batch_size", 24),
warmup_steps=component_config.get("warmup_steps", 500),
weight_decay=component_config.get("weight_decay", 0.01),
learning_rate=component_config.get("learning_rate", 2e-5),
lr_scheduler_type=component_config.get("scheduler_type", "constant"),
save_strategy="no",
)
trainer = Trainer(
model=self.model,
args=training_args,
train_dataset=dataset,
compute_metrics=compute_metrics,
)
trainer.train()
self.persist()
return self._resource
def _process_intent_ranking(self, outputs):
"""
Processes the intent ranking, sort in descending order based on confidence. Get only top 10
Args:
outputs: model outputs
Returns:
intent_ranking (list) - list of dicts with intent name and confidence (top 10 only)
"""
confidences = [float(x) for x in outputs["logits"][0]]
intent_names = list(self.label2id.keys())
intent_ranking_all = zip(confidences, intent_names)
intent_ranking_all_sorted = sorted(
intent_ranking_all, key=lambda x: x[0], reverse=True
)
intent_ranking = [
{"confidence": x[0], "intent": x[1]} for x in intent_ranking_all_sorted[:10]
]
return intent_ranking
def _predict(self, text):
"""
Predicts the intent of the input text.
Args:
text (str): input text
Returns:
prediction (string) - intent name
confidence (float) - confidence of the intent
intent_ranking (list) - list of dicts with intent name and confidence (top 10 only)
"""
component_config = self.get_default_config()
inputs = self.tokenizer(
text,
padding="max_length",
max_length=component_config.get("max_length", 64),
truncation=True,
return_tensors="pt",
).to(DEVICE)
print("_predict -> inputs: {}".format(inputs))
outputs = self.model(**inputs)
print("_predict -> outputs: {}".format(outputs))
confidence = float(outputs["logits"][0].max())
prediction = self.id2label[int(outputs["logits"][0].argmax())]
intent_ranking = self._process_intent_ranking(outputs)
return prediction, confidence, intent_ranking
def process(self, messages: List[Message]) -> List[Message]:
"""
Processes the input given from Rasa. Attaches the output to the message object.
Args:
message (Message): input message
"""
for message in messages:
text = message.data["text"]
prediction, confidence, intent_ranking = self._predict(text)
message.set(
"intent", {"name": prediction, "confidence": confidence}, add_to_output=True
)
message.set("intent_ranking", intent_ranking, add_to_output=True)
return messages
def process_training_data(self, training_data):
self.process(training_data.training_examples)
return training_data
def persist(self) -> None:
with self._model_storage.write_to(self._resource) as model_dir:
tokenizer_filename = "tokenizer_{}".format(self.name)
model_filename = "model_{}".format(self.name)
config_filename = "config_{}".format(self.name)
tokenizer_path = os.path.join(model_dir, tokenizer_filename)
model_path = os.path.join(model_dir, model_filename)
config_path = os.path.join(model_dir, config_filename)
self.tokenizer.save_pretrained(tokenizer_path)
self.model.save_pretrained(model_path)
self.config.save_pretrained(config_path)
# @classmethod
# def load(
# cls, meta, model_dir=None, model_metadata=None, cached_component=None, **kwargs
# ):
# """
# Loads the model, tokenizer and configuration from the given path.
# Returns:
# component (Component): loaded component
# """
# tokenizer_filename = meta.get("tokenizer")
# model_filename = meta.get("model")
# config_filename = meta.get("config")
# tokenizer_path = os.path.join(model_dir, tokenizer_filename)
# model_path = os.path.join(model_dir, model_filename)
# config_path = os.path.join(model_dir, config_filename)
# x = cls(meta)
# x.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
# x.config = AutoConfig.from_pretrained(config_path)
# x.id2label = x.config.id2label
# x.label2id = x.config.label2id
# x.model = AutoModelForSequenceClassification.from_pretrained(
# model_path, config=x.config
# ).to(DEVICE)
# return x
@classmethod
def load(
cls,
config: Dict[Text, Any],
model_storage: ModelStorage,
resource: Resource,
execution_context: ExecutionContext,
) -> GraphComponent:
with model_storage.read_from(resource) as model_dir:
component = cls(
config, execution_context.node_name, model_storage, resource
)
tokenizer_filename = config["tokenizer"]
model_filename = config["model"]
config_filename = config["config"]
tokenizer_path = os.path.join(model_dir, tokenizer_filename)
model_path = os.path.join(model_dir, model_filename)
config_path = os.path.join(model_dir, config_filename)
component.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
component.config = AutoConfig.from_pretrained(config_path)
component.id2label = component.config.id2label
component.label2id = component.config.label2id
component.model = AutoModelForSequenceClassification.from_pretrained(
model_path, config=component.config
).to(DEVICE)
return component
The full error is this one:
Traceback (most recent call last):
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/engine/graph.py", line 496, in __call__
output = self._fn(self._component, **run_kwargs)
File "/Users/endlessrecurrence/Documents/Repos/rasa-fnet-experiment/transformer_classifier.py", line 217, in train
trainer.train()
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/transformers/trainer.py", line 1624, in train
return inner_training_loop(
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/transformers/trainer.py", line 1961, in _inner_training_loop
tr_loss_step = self.training_step(model, inputs)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/transformers/trainer.py", line 2902, in training_step
loss = self.compute_loss(model, inputs)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/transformers/trainer.py", line 2925, in compute_loss
outputs = model(**inputs)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
return forward_call(*args, **kwargs)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/transformers/models/albert/modeling_albert.py", line 1105, in forward
loss = loss_fct(logits, labels)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1511, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
return forward_call(*args, **kwargs)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/torch/nn/modules/loss.py", line 725, in forward
return F.binary_cross_entropy_with_logits(input, target,
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/torch/nn/functional.py", line 3197, in binary_cross_entropy_with_logits
raise ValueError(f"Target size ({target.size()}) must be the same as input size ({input.size()})")
ValueError: Target size (torch.Size([24])) must be the same as input size (torch.Size([24, 0]))
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/bin/rasa", line 8, in <module>
sys.exit(main())
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/__main__.py", line 133, in main
cmdline_arguments.func(cmdline_arguments)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/cli/train.py", line 61, in <lambda>
train_parser.set_defaults(func=lambda args: run_training(args, can_exit=True))
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/cli/train.py", line 101, in run_training
training_result = train_all(
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/api.py", line 105, in train
return train(
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/model_training.py", line 207, in train
return _train_graph(
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/model_training.py", line 286, in _train_graph
trainer.train(
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/engine/training/graph_trainer.py", line 105, in train
graph_runner.run(inputs={PLACEHOLDER_IMPORTER: importer})
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/engine/runner/dask.py", line 101, in run
dask_result = dask.get(run_graph, run_targets)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/local.py", line 557, in get_sync
return get_async(
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/local.py", line 500, in get_async
for key, res_info, failed in queue_get(queue).result():
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/concurrent/futures/_base.py", line 439, in result
return self.__get_result()
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/concurrent/futures/_base.py", line 391, in __get_result
raise self._exception
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/local.py", line 542, in submit
fut.set_result(fn(*args, **kwargs))
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/local.py", line 238, in batch_execute_tasks
return [execute_task(*a) for a in it]
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/local.py", line 238, in <listcomp>
return [execute_task(*a) for a in it]
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/local.py", line 229, in execute_task
result = pack_exception(e, dumps)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/local.py", line 224, in execute_task
result = _execute_task(task, data)
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/dask/core.py", line 119, in _execute_task
return func(*(_execute_task(a, cache) for a in args))
File "/Users/endlessrecurrence/anaconda3/envs/py3_9_chatbot/lib/python3.9/site-packages/rasa/engine/graph.py", line 503, in __call__
raise GraphComponentException(
rasa.engine.exceptions.GraphComponentException: Error running graph component for node train_transformer_classifier.TransformerClassifier3.
Another detail that is very interesting is the fact that the model expects a target value with the (24, 0) shape, which is absurd! I’ve read that there are actually tensors with a zero dimension, but what is the exact reason for that? Why would I want to use a tensor with a zero dimension?
I would be very grateful if you guys could give me some hints or advice to get rid of this newbie issue. Thanks.