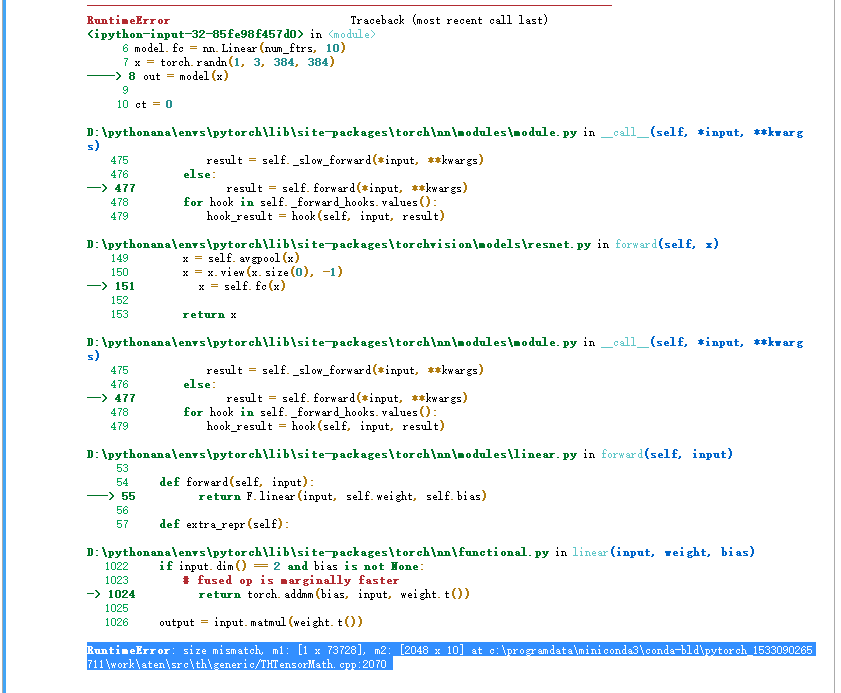
I am running finetuning resnt50 to realize multi-label annotation. But it comes out the problem: RuntimeError: size mismatch, m1: [2 x 73728], m2: [2048 x 1000] at c:\programdata\miniconda3\conda-bld\pytorch_1533090265711\work\aten\src\thc\generic/THCTensorMathBlas.cu:249
Here are the codes:
from collections import defaultdict
train_results = defaultdict(list)
train_iter, test_iter, best_acc = 0,0,0
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize = (10, 10))
ax1.set_title(‘Train Loss’)
ax2.set_title(‘Train Accuracy’)
ax3.set_title(‘Test Loss’)
ax4.set_title(‘Test Accuracy’)
f1_scores = defaultdict(list)
for i in tnrange(epochs, desc=‘Epochs’):
print("Epoch ",i)
## Train Phase
#Model switches to train phase
model.train()
all_outputs = []
all_targets = []
# Running through all mini batches in the dataset
count, loss_val, correct, total = train_iter, 0, 0, 0
for img_data, target in tqdm_notebook(train_loader, desc='Training'):
img_data, target = img_data.to(device), target.to(device)
output = model(img_data) #FWD prop
loss = criterion(output, target) #Cross entropy loss
c_loss = loss.data.item()
ax1.plot(count, c_loss, 'r.')
loss_val += c_loss
optimizer.zero_grad() #Zero out any cached gradients
loss.backward() #Backward pass
optimizer.step() #Update the weights
total_batch = (target.size(0) * target.size(1))
total += total_batch
output_data = torch.sigmoid(output)>=0.5
target_data = (target==1.0)
for arr1,arr2 in zip(output_data, target_data):
all_outputs.append(list(arr1.cpu().numpy()))
all_targets.append(list(arr2.cpu().numpy()))
c_acc = torch.sum((output_data == target_data.to(device)).to(torch.float)).item()
ax2.plot(count, c_acc/total_batch, 'r.')
correct += c_acc
count +=1
all_outputs = np.array(all_outputs)
all_targets = np.array(all_targets)
f1score_samples = f1_score(y_true=all_targets, y_pred=all_outputs, average='samples')
f1score_macro = f1_score(y_true=all_targets, y_pred=all_outputs, average='macro')
f1score_weighted = f1_score(y_true=all_targets, y_pred=all_outputs, average='weighted')
recall = recall_score(y_true=all_targets, y_pred=all_outputs, average='samples')
prec = precision_score(y_true=all_targets, y_pred=all_outputs, average='samples')
hamming = hamming_score(y_true=all_targets, y_pred=all_outputs)
f1_scores["samples_train"].append(f1score_samples)
f1_scores["macro_train"].append(f1score_macro)
f1_scores["weighted_train"].append(f1score_weighted)
f1_scores["hamming_train"].append(hamming)
train_loss_val, train_iter, train_acc = loss_val/len(train_loader.dataset), count, correct/float(total)
print("Training loss: ", train_loss_val, " train acc: ",train_acc)
## Test Phase
#Model switches to test phase
model.eval()
all_outputs = []
all_targets = []
#Running through all mini batches in the dataset
count, correct, total, lost_val = test_iter, 0, 0, 0
for img_data, target in tqdm_notebook(val_loader, desc='Testing'):
img_data, target = img_data.to(device), target.to(device)
output = model(img_data)
loss = criterion(output, target) #Cross entropy loss
c_loss = loss.data.item()
ax3.plot(count, c_loss, 'b.')
loss_val += c_loss
#Compute accuracy
#predicted = output.data.max(1)[1] #get index of max
total_batch = (target.size(0) * target.size(1))
total += total_batch
output_data = torch.sigmoid(output)>=0.5
target_data = (target==1.0)
#print("Predictions: ", output_data)
#print("Actual: ", target_data)
for arr1,arr2 in zip(output_data, target_data):
all_outputs.append(list(arr1.cpu().numpy()))
all_targets.append(list(arr2.cpu().numpy()))
c_acc = torch.sum((output_data == target_data.to(device)).to(torch.float)).item()
ax4.plot(count, c_acc/total_batch, 'b.')
correct += c_acc
count += 1
#print("Outputs: ", len(all_outputs), " x ", len(all_outputs[0]))
#print("Targets: ", len(all_targets), " x ", len(all_targets[0]))
#F1 Score
all_outputs = np.array(all_outputs)
all_targets = np.array(all_targets)
f1score_samples = f1_score(y_true=all_targets, y_pred=all_outputs, average='samples')
f1score_macro = f1_score(y_true=all_targets, y_pred=all_outputs, average='macro')
f1score_weighted = f1_score(y_true=all_targets, y_pred=all_outputs, average='weighted')
recall = recall_score(y_true=all_targets, y_pred=all_outputs, average='samples')
prec = precision_score(y_true=all_targets, y_pred=all_outputs, average='samples')
hamming = hamming_score(y_true=all_targets, y_pred=all_outputs)
f1_scores["samples_test"].append(f1score_samples)
f1_scores["macro_test"].append(f1score_macro)
f1_scores["weighted_test"].append(f1score_weighted)
f1_scores["hamming_test"].append(hamming)
#Accuracy over entire dataset
test_acc, test_iter, test_loss_val = correct/float(total), count, loss_val/len(test_loader.dataset)
print("Test set accuracy: ",test_acc)
train_results['epoch'].append(i)
train_results['train_loss'].append(train_loss_val)
train_results['train_acc'].append(train_acc)
train_results['train_iter'].append(train_iter)
train_results['test_loss'].append(test_loss_val)
train_results['test_acc'].append(test_acc)
train_results['test_iter'].append(test_iter)
#Save model with best accuracy
if test_acc > best_acc:
best_acc = test_acc
torch.save(model.state_dict(), 'best_model.pth')
fig.savefig(‘train_curves.png’)