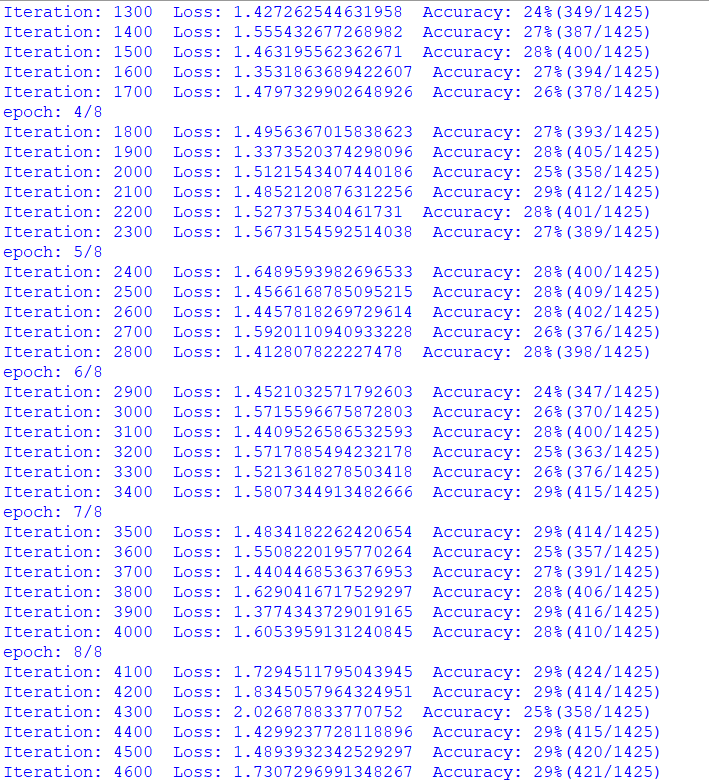
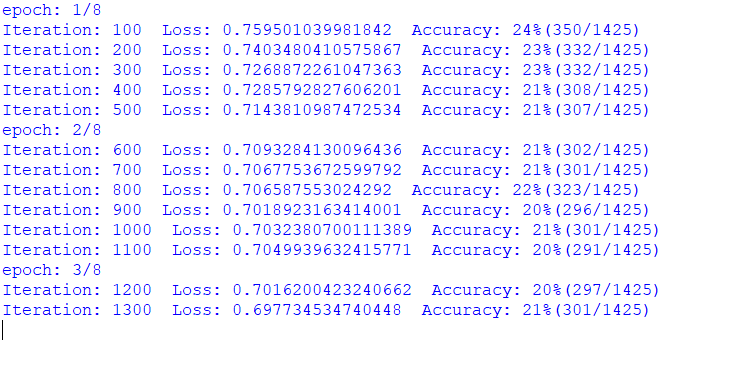
i am trying image classification with this dataset and i resize them (64, 64). but my test accuracy is unstable and so low. my model:
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5)
self.conv3 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=5)
self.norm1 = nn.InstanceNorm2d(64)
self.maxpool1 = nn.MaxPool2d(3)
self.relu1 = nn.LeakyReLU()
self.conv4 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=5)
self.conv5 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=5)
self.conv6 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=5)
self.norm2 = nn.InstanceNorm2d(256)
self.maxpool2 = nn.MaxPool2d(3)
self.relu2 = nn.LeakyReLU()
self.fc1 = nn.Linear(256, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 60)
self.fc4 = nn.Linear(60, 50)
self.fc5 = nn.Linear(50, 40)
self.fc6 = nn.Linear(40, 30)
self.fc7 = nn.Linear(30, 20)
self.fc8 = nn.Linear(20, 10)
self.fc9 = nn.Linear(10, 5)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.conv1(x)
out = self.conv2(out)
out = self.conv3(out)
out = self.norm1(out)
out = self.maxpool1(out)
out = self.relu1(out)
out = self.conv4(out)
out = self.conv5(out)
out = self.conv6(out)
out = self.norm2(out)
out = self.maxpool2(out)
out = self.relu2(out)
# flatten
out = out.view(out.size(0), -1)
out = self.fc1(out)
out = self.fc2(out)
out = self.fc3(out)
out = self.fc4(out)
out = self.fc5(out)
out = self.fc6(out)
out = self.fc7(out)
out = self.fc8(out)
out = self.sigmoid(self.fc9(out))
return out
my train func:
batch_size = 5
n_iters = 5000
num_epochs = n_iters / (len(train) / batch_size)
num_epochs = int(num_epochs)
trainDatas = DataLoader(train, batch_size=batch_size, shuffle=True)
testDatas = DataLoader(test, batch_size=batch_size, shuffle=True)
# Create model
model = CNNModel()
# Cross Entropy Loss
error = nn.CrossEntropyLoss()
learning_rate = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
count = 0
loss_list = []
iteration_list = []
accuracy_list = []
best_correct = 0.0
model = model.float()
for epoch in range(num_epochs):
print('epoch: {}/{}'.format(epoch+1, num_epochs))
for i, (train, label) in enumerate(trainDatas):
# train mode
model.train()
train = Variable(train)
label = Variable(label)
# Clear gradients
optimizer.zero_grad()
# forward propagation
outputs = model(train.float())
_, label = torch.max(label.data, 1)
loss = error(outputs, label.long())
loss.backward()
optimizer.step()
count += 1
if count % 50 == 0:
# Calculate Accuracy
correct = 0
total = 0
# predict test dataset
for j, (test, testLabel) in enumerate(testDatas):
# predict mode
model.eval()
test = Variable(test)
testLabel = Variable(testLabel)
# forward propagation
outputs = model(test.float())
_, pred = torch.max(outputs, 1)
_, testLabel = torch.max(testLabel.data, 1)
correct += torch.sum(pred == testLabel)
total = len(testDatas)
accuracy = 100 * (correct / (float(j)*batch_size))
if correct > best_correct:
torch.save(model, 'best.model')
best_correct = correct
# store loss and iteration
loss_list.append(loss.data)
iteration_list.append(count)
accuracy_list.append(accuracy)
if count % 100 == 0:
print('Iteration: {} Loss: {} Accuracy: {}%({}/{})'.format(
count, loss.data, int(accuracy), correct, total*batch_size))
and a train example: