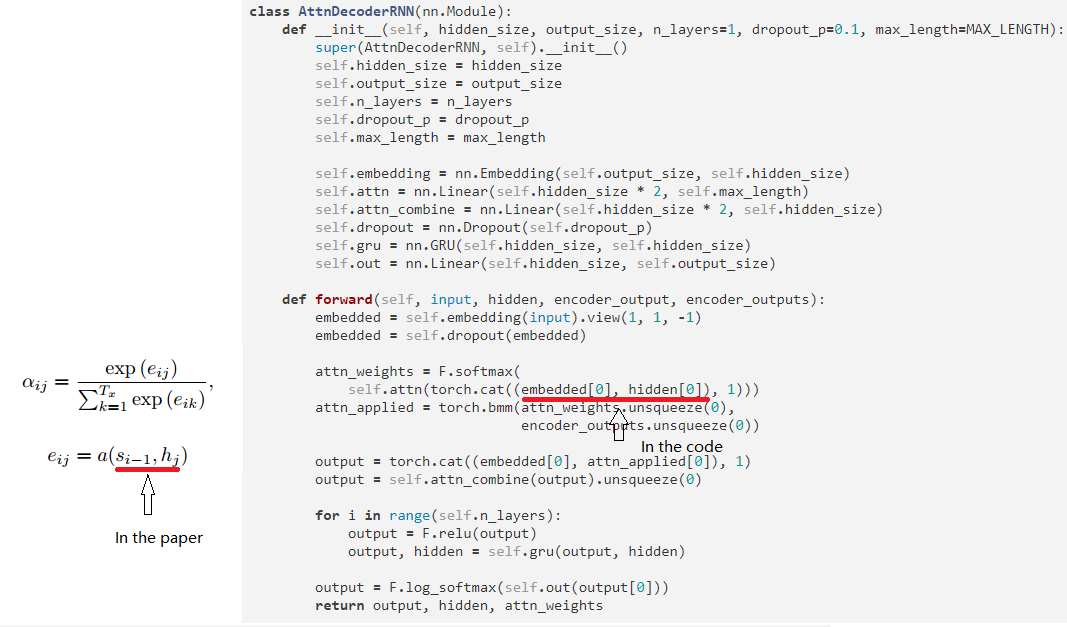
I have tag the difference with red line.Once you read the paper and the code you will find the difference.
What is strange is that it woks properly! Why?Am I wrong?
The code looks correct to me. If I understand correctly this a cell of a decoder RNN. The input then is exactly s_{i-1} and hidden is h_j.
Disclaimer: I didn’t actually read the paper nor the code.
Btw, if you have already read through the paper and the code, then why don’t you tell us what the notations mean and what these variables represent? Having to read paper+code to answer your question is quite time-consuming.
I’m sorry that I haven’t explain what the notations mean. I 'm just a student and rarely ask questions online.So please forgive me for making the mistake.
I think s_{i-1} is the (i-1)-th hidden state of decoder, and h_{j} is the j-th output of encoder.But in the code, embeded[0] is the input embedding of this decoder cell, and hidden[0] is hidden output of last decoder cell. How can we caculate attention weight without the information of encoder? Maybe I misunderstood the meaning of notations…
Maybe only the one who have read both paper and code can help me… Thanks a lot.