RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 2.00 GiB total capacity; 1.28 GiB already allocated; 4.55 MiB free; 1.28 GiB reserved in total by PyTorch) The Script that I run:Pytorch script for fine-tuning Pegasus Large model · GitHub
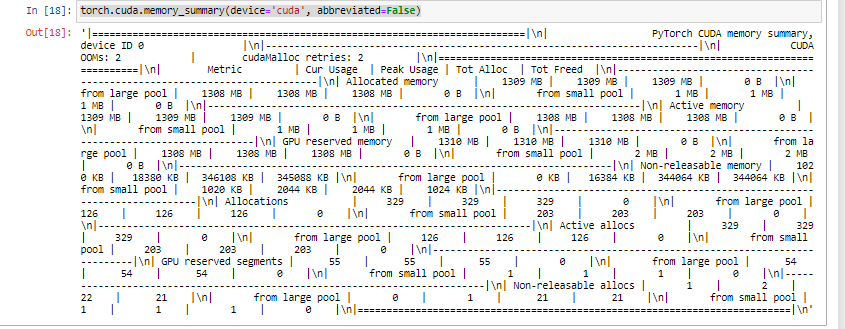
Note: The batch size in the script is 1 and I ran the following to see more details torch.cuda.memory_summary(device=‘cuda’, abbreviated=False) and this was the output:
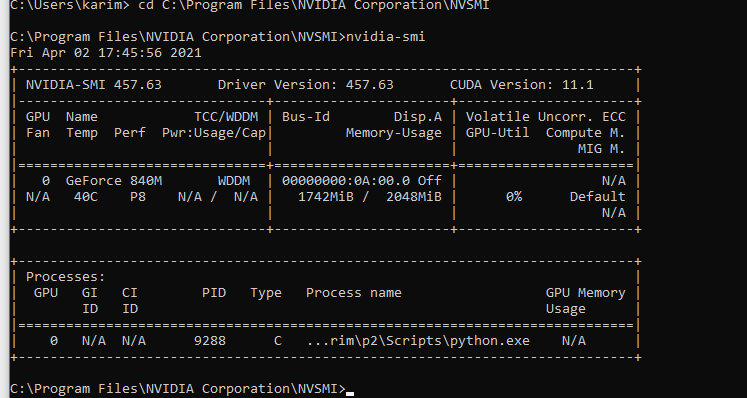
Could you check, if the GPU is completely empty before running the script via nvidia-smi?
2GB device memory is not a lot, but I assume you were able to run the script with a batch size of one before?
torch.cuda.memory_summary() will report, what PyTorch is using and not if other processes might also use device memory, so you would have to use e.g. nvidia-smi.
I think you executed your script before launchingnvidia-smi, do you confirm that ? If it’s not the case, kill the script that is consuming GPU and run your code.
I found out that the problem was that my GPU memory is about 2GB while the recommended memory size is 16 GB.
Upon this I subscribed to Colab Pro as it provides 16 GB of GPU memory and enough disk space to run the script. Here is the link to the issue on github which also contain some tips were mentioned by one of the contributors that might help others0