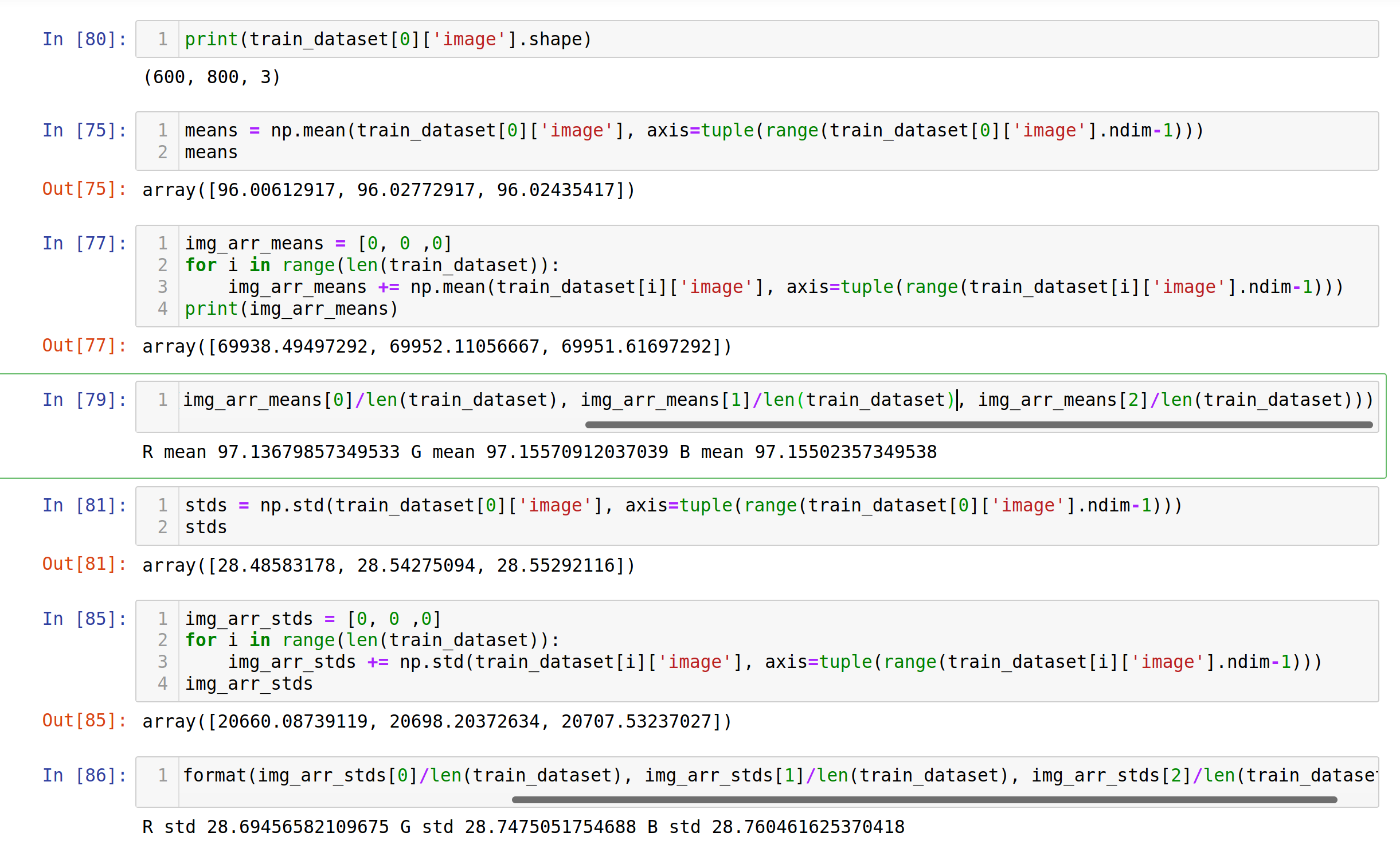
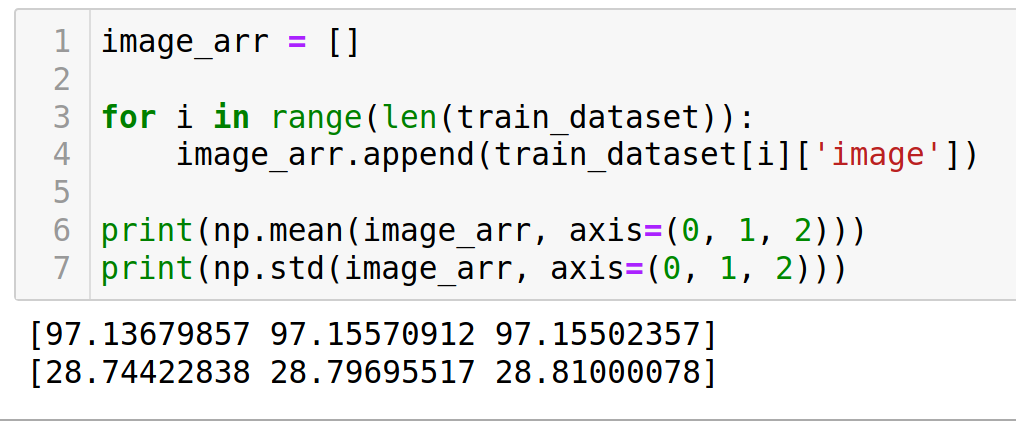
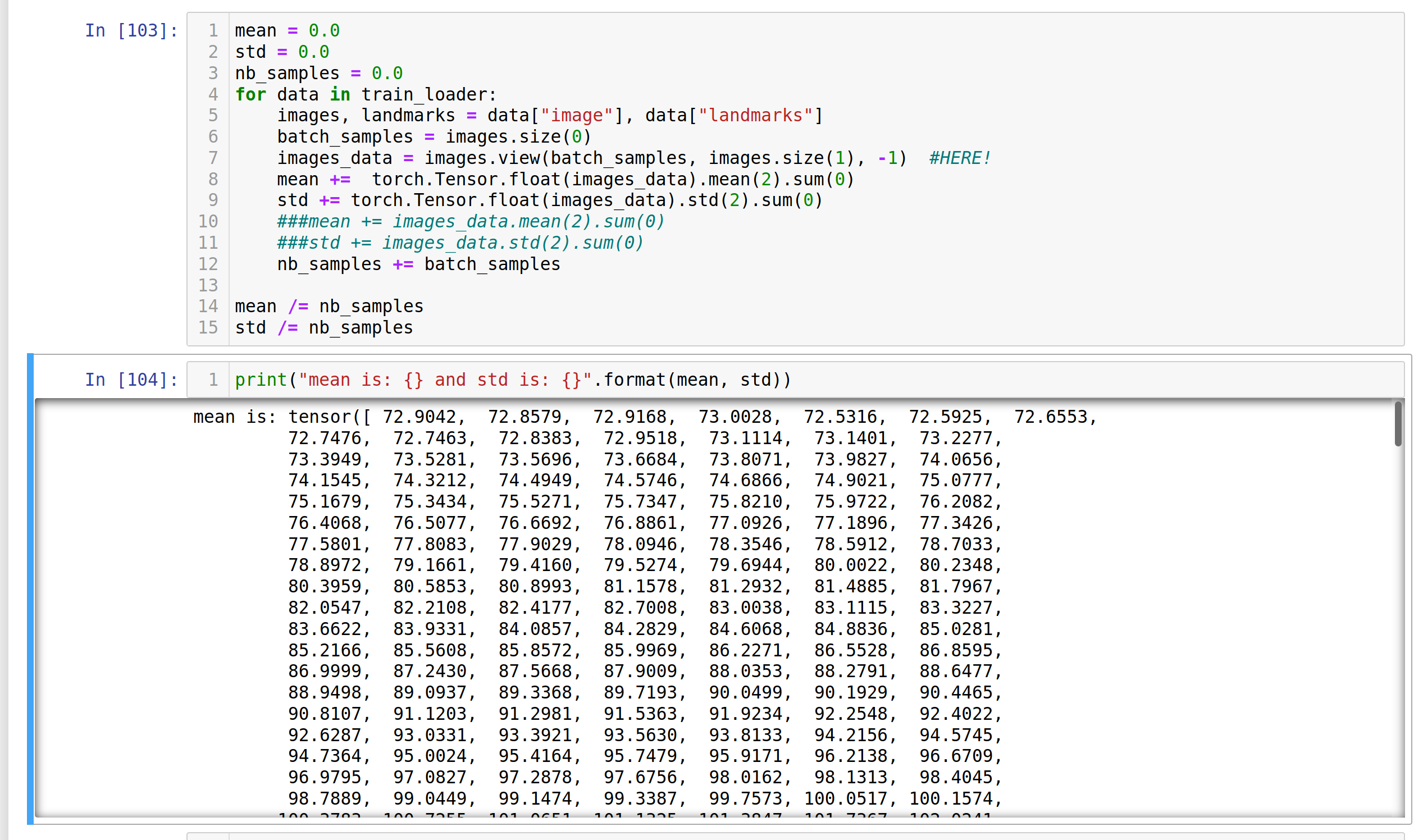
I am trying to Normalize my images data and for that I need to find the mean and std for train_loader.
mean = 0.0
std = 0.0
nb_samples = 0.0
for data in train_loader:
images, landmarks = data["image"], data["landmarks"]
batch_samples = images.size(0)
images_data = images.view(batch_samples, images.size(1), -1)
mean += torch.Tensor.float(images_data).mean(2).sum(0)
std += torch.Tensor.float(images_data).std(2).sum(0)
###mean += images_data.mean(2).sum(0)
###std += images_data.std(2).sum(0)
nb_samples += batch_samples
mean /= nb_samples
std /= nb_samples
the mean and std here are each a torch.Size([600])
When I tried (almost) same code on dataloader, it worked as expected:
# code from https://discuss.pytorch.org/t/about-normalization-using-pre-trained-vgg16-networks/23560/6?u=mona_jalal
mean = 0.0
std = 0.0
nb_samples = 0.0
for data in dataloader:
images, landmarks = data["image"], data["landmarks"]
batch_samples = images.size(0)
images_data = images.view(batch_samples, images.size(1), -1)
mean += images_data.mean(2).sum(0)
std += images_data.std(2).sum(0)
nb_samples += batch_samples
mean /= nb_samples
std /= nb_samples
and I got:
mean is: tensor([0.4192, 0.4195, 0.4195], dtype=torch.float64), std is: tensor([0.1182, 0.1184, 0.1186], dtype=torch.float64)
So my dataloader is:
class MothLandmarksDataset(Dataset):
"""Face Landmarks dataset."""
def __init__(self, csv_file, root_dir, transform=None):
"""
Args:
csv_file (string): Path to the csv file with annotations.
root_dir (string): Directory with all the images.
transform (callable, optional): Optional transform to be applied
on a sample.
"""
self.landmarks_frame = pd.read_csv(csv_file)
self.root_dir = root_dir
self.transform = transform
def __len__(self):
return len(self.landmarks_frame)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
img_name = os.path.join(self.root_dir, self.landmarks_frame.iloc[idx, 0])
image = io.imread(img_name)
landmarks = self.landmarks_frame.iloc[idx, 1:]
landmarks = np.array([landmarks])
landmarks = landmarks.astype('float').reshape(-1, 2)
sample = {'image': image, 'landmarks': landmarks}
if self.transform:
sample = self.transform(sample)
return sample
transformed_dataset = MothLandmarksDataset(csv_file='moth_gt.csv',
root_dir='.',
transform=transforms.Compose(
[
Rescale(256),
RandomCrop(224),
ToTensor()
]
)
)
dataloader = DataLoader(transformed_dataset, batch_size=3,
shuffle=True, num_workers=4)
and train_loader is:
# Device configuration
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
seed = 42
np.random.seed(seed)
torch.manual_seed(seed)
# split the dataset into validation and test sets
len_valid_set = int(0.1*len(dataset))
len_train_set = len(dataset) - len_valid_set
print("The length of Train set is {}".format(len_train_set))
print("The length of Test set is {}".format(len_valid_set))
train_dataset , valid_dataset, = torch.utils.data.random_split(dataset , [len_train_set, len_valid_set])
# shuffle and batch the datasets
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=8, shuffle=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=8, shuffle=True, num_workers=4)
Please let me know if more information is needed.
I basically need to get 3 values for mean of train_loader and 3 values for std of train_loader to use as args for Normalize.
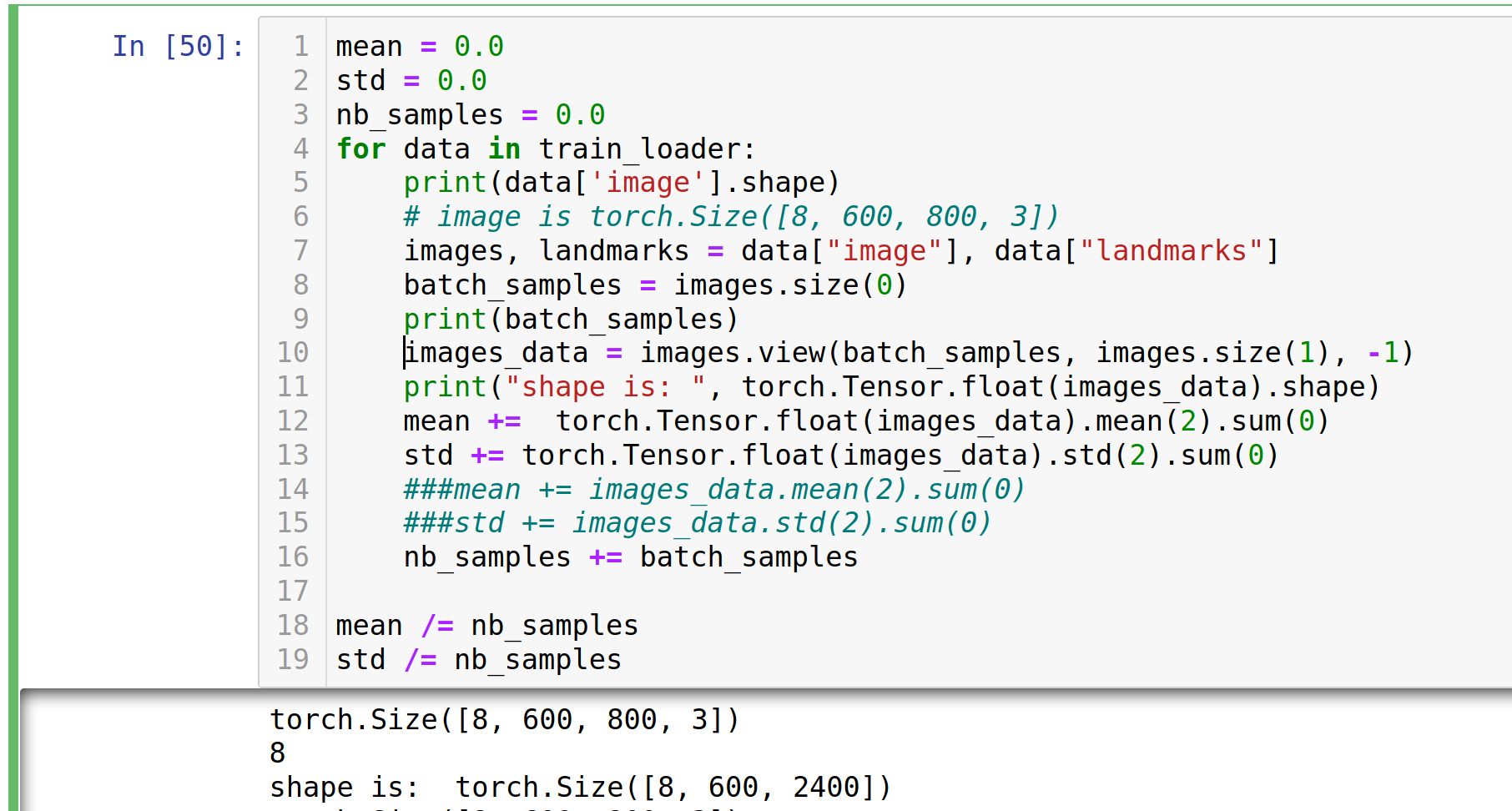
images_data in dataloader is torch.Size([3, 3, 50176]) inside the loop and images_data in train_loader is torch.Size([8, 600, 2400])
8 in torch.Size([8, 600, 2400]) for train_loader refers to the batch_size I have set for trainset