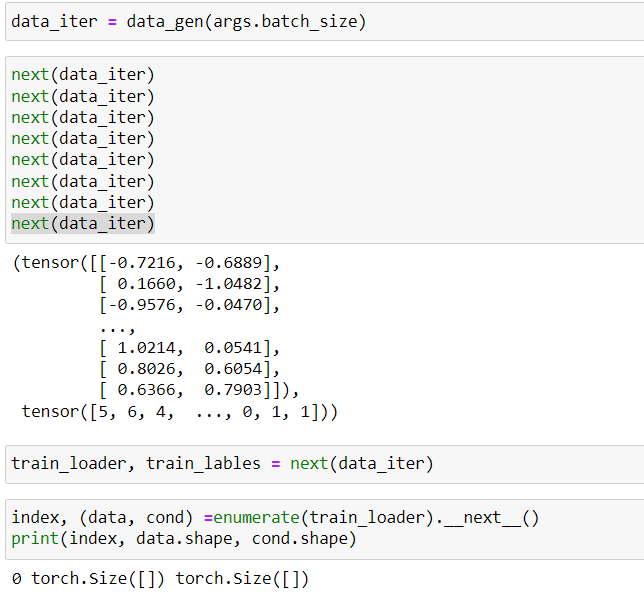
for adding conditions to VAE I used this data set and labels but I got an error in part of the code:
here is my data generator:
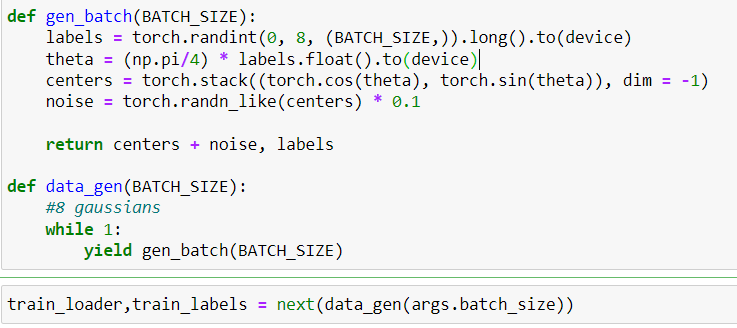
and I got an error in this part:

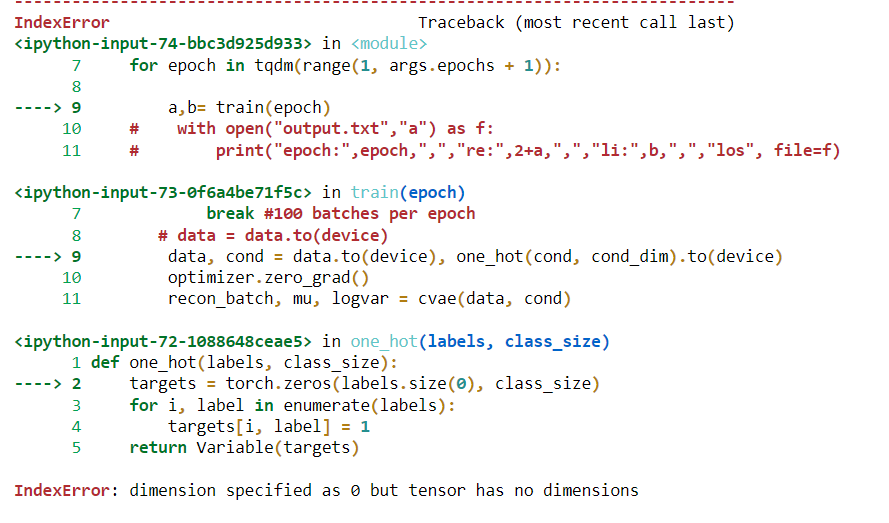
how can I fix it?
labels seems to be a scalar and thus doesn’t have dimensions:
labels = torch.tensor(1.)
print(labels.shape)
> torch.Size([])
labels.size(0)
> IndexError: dimension specified as 0 but tensor has no dimensions
Make sure cond is created as a tensor with the expected number of dimensions.
@ptrblck Thanks. Could the problem be from this line?
train_loader,train_labels = next(data_gen(args.batch_size))
I tried to use pytorch dataloader but I got this error:
TypeError: object of type ‘generator’ has no len()
I used the same method of adding condition with MNIST dataset, but my dataset is different
Based on your code snippet you are not using a DataLoader, but are creating a custom generator, so I’m unsure where the error is coming from.
Could you post a minimal, executable code snippet to reproduce the issue?
@ptrblck . No I am not using DataLoader but maybe I have to change my generator and add length on it!? then using DataLoader? here is the code and I am adding conditioning to VAE
K = int(input("Enter K:"))
# construct the argument parser and parser the arguments
parser = argparse.ArgumentParser(description='VAE Example')
parser.add_argument('--batch-size', type=int, default=2048, metavar='N',
help='input batch size for training (default: 128)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
args = parser.parse_args()
torch.manual_seed(args.seed)
# we use CPU for computation
#device = torch.device("cpu")
use_cuda = torch.cuda.is_available()
device = torch.device("cuda:0" if use_cuda else "cpu")
def gen_batch(BATCH_SIZE):
labels = torch.randint(0, 8, (BATCH_SIZE,)).long().to(device)
theta = (np.pi/4) * labels.float().to(device)
centers = torch.stack((torch.cos(theta), torch.sin(theta)), dim = -1)
noise = torch.randn_like(centers) * 0.1
return centers + noise, labels
def data_gen(BATCH_SIZE):
#8 gaussians
while 1:
yield gen_batch(BATCH_SIZE)
train_loader,train_labels = next(data_gen(args.batch_size))
test_loader = train_loader
cond_dim = train_labels.unique().size(0)
class CVAE(nn.Module):
def __init__(self, c_dim):
super(CVAE, self).__init__()
# encoder part
self.fc0 = nn.Linear(2 + c_dim, K)
self.fc1 = nn.Linear(K, K)
self.fc21 = nn.Linear(K, K)
self.fc22 = nn.Linear(K, K)
# decoder part
self.fc3 = nn.Linear(K + c_dim, K)
self.fc4 = nn.Linear(K, K)
self.fc5 = nn.Linear(K, 2)
def encode(self, x, c):
concat_input = torch.cat([x, c], 1)
h1 = F.selu(self.fc1(F.selu(self.fc0(concat_input))))
return self.fc21(h1), self.fc22(h1)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5*logvar)
eps = torch.randn_like(std)
return mu + eps*std
def sample(self, n=2048):
"""
Generate n samples from the generative model.
"""
sample = torch.randn(n, K).to(device)
out = cvae.decode(sample)
return out.cpu().detach().numpy()
def decode(self, z, c):
concat_input = torch.cat([z, c], 1)
return self.fc5(F.selu(self.fc4(F.selu(self.fc3(concat_input)))))
def forward(self, x, c):
mu, logvar = self.encode(x.view(-1, 2), c)
z = self.reparameterize(mu, logvar)
return self.decode(z, c), mu, logvar
cvae = CVAE(c_dim=cond_dim).to(device)
optimizer = optim.Adam(cvae.parameters(), lr=1e-3)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, verbose = True, threshold = 1E-2, eps=1e-6)
# Reconstruction + KL divergence losses summed over all elements and batch
def loss_function(recon_x, x, mu, logvar):
#BCE = F.binary_cross_entropy(recon_x, x.view(-1, 2), reduction='sum')
L2 = torch.mean((recon_x-x)**2)
# see Appendix B from VAE paper:
# Kingma and Welling. Auto-Encoding Variational Bayes. ICLR, 2014
# https://arxiv.org/abs/1312.6114
# 0.5 * sum(1 + log(sigma^2) - mu^2 - sigma^2)
KLD = -0.5 * torch.mean(1 + logvar - mu.pow(2) - logvar.exp())
return L2 + KLD
def one_hot(labels, class_size):
targets = torch.zeros(labels.size(0), class_size)
for i, label in enumerate(labels):
targets[i, label] = 1
return Variable(targets)
def train(epoch):
cvae.train()
train_loss = 0
for batch_idx, (data,cond) in enumerate(train_loader):
if batch_idx > 100:
break #100 batches per epoch
# data = data.to(device)
data, cond = data.to(device), one_hot(cond, cond_dim).to(device)
optimizer.zero_grad()
recon_batch, mu, logvar = cvae(data, cond)
print("mu", mu)
print("logvar", logvar)
loss = loss_function(recon_batch, data, mu, logvar)
recon_batch = recon_batch.detach().numpy()
loss.backward()
train_loss += loss.item()
optimizer.step()
train_loss /= 100
scheduler.step(train_loss)
samples_model = cvae.sample()
samples_gt = gen_batch(2048)
kde_skl = KernelDensity(kernel='gaussian', bandwidth=0.2)
kde_skl.fit(samples_gt)
# score_samples() returns the log-likelihood of the samples
log_pdf = kde_skl.score_samples(samples_model)
print ("Epoch average reconstruction error :" ,epoch , train_loss)
print (" likelihood :", np.mean(log_pdf))
return train_loss, np.mean(log_pdf)
if __name__ == "__main__":
print("Starting training....")
train_5 = []
log_5 = []
for epoch in tqdm(range(1, args.epochs + 1)):
a,b= train(epoch)
# with open("output.txt","a") as f:
# print("epoch:",epoch,",","re:",2+a,",","li:",b,",","los", file=f)
# print("VAL ---","re:",2+a,",","li:",b,",","los", file=f)
# print("update best loss", file=f)
gt = next(train_loader)
with torch.no_grad():
out1 = cvae.sample()
recon = cvae(gt)[0].cpu().numpy()
rx,ry = recon[:,0], recon[:,1]
gt = gt.cpu().numpy()
gx, gy = gt[:,0], gt[:,1]
xs, ys = out1[:,0], out1[:,1]
plt.scatter(gx, gy, c = 'red', s=3)
plt.scatter(xs, ys, c = 'blue', s=3)
plt.axes().set_aspect('equal')
plt.show()
In your current code snippet you are assigning train_loader to the input batch, not a “loader” or generator object.
If you want to use your custom generator, create an iterator and call next on it:
data_iter = data_gen(args.batch_size)
next(data_iter)
next(data_iter)
next(data_iter)
next(data_iter)
@ptrblck sorry but how should I use it? I still get the same error
IndexError: dimension specified as 0 but tensor has no dimensions
next(data_iter) will return a data and target sample, not a DataLoader.
If I execute your code, index, (data, cond) = enumerate(train_loader).__next__() will return the first two values from the data sample, so I don’t think that’s what you want to use.
If you want to create a custom iterator and get the next sample, use next(data_iter) in your training loop.
Thanks, it works but now I got this error:
<ipython-input-112-4098c099a02e> in sample(self, n)
28 """
29 sample = torch.randn(n, K).to(device)
---> 30 out = cvae.decode(sample, cond_dim)
31
32 return out.cpu().detach().numpy()
<ipython-input-112-4098c099a02e> in decode(self, z, c)
34
35 def decode(self, z, c):
---> 36 concat_input = torch.cat([z, c], 1)
37 return self.fc5(F.selu(self.fc4(F.selu(self.fc3(concat_input)))))
38
TypeError: expected Tensor as element 1 in argument 0, but got int
Is it because of torch.cat?
Yes, I guess you are passing z or c as an int while a tensor is expected:
z, c = torch.randn(1, 1), torch.randn(1, 1)
out = torch.cat([z, c], dim=1) # works if both inputs are tensors
c = 1
out = torch.cat([z, c], dim=1)
# > TypeError: expected Tensor as element 0 in argument 0, but got int
@ptrblck , here the inputs of the decoder are (sample, con_dim). con_dim was int I changed that to tensor but now I got this error:
---> 31 samples_model = cvae.sample()
32 samples_gt = gen_batch(2048)
33 kde_skl = KernelDensity(kernel='gaussian', bandwidth=0.2)
<ipython-input-86-826f0d9710ca> in sample(self, n)
28 """
29 sample = torch.randn(n, K).to(device)
---> 30 out = cvae.decode(sample, cond_dim)
31
32 return out.cpu().detach().numpy()
<ipython-input-86-826f0d9710ca> in decode(self, z, c)
34
35 def decode(self, z, c):
---> 36 concat_input = torch.cat([z, c], 1)
37 return self.fc5(F.selu(self.fc4(F.selu(self.fc3(concat_input)))))
38
RuntimeError: zero-dimensional tensor (at position 1) cannot be concatenated
because the size of sample is 2048x20 but cond_dim has no dimension
cond_dim.shape
torch.Size([])
Then I tried to use torch.stack instead of torch.cat for k=8 but I got the following error, I think the logic of my choice for condition is wrong and every time I got new error:((
<ipython-input-73-3eb5f1d14a58> in train(epoch)
16 data, cond = data.to(device), one_hot(cond, cond_dim).to(device)
17 optimizer.zero_grad()
---> 18 recon_batch, mu, logvar = cvae(data, cond)
19 print("mu", mu)
20 print("logvar", logvar)
~\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
<ipython-input-68-127374cfac97> in forward(self, x, c)
40 mu, logvar = self.encode(x.view(-1, 2), c)
41 z = self.reparameterize(mu, logvar)
---> 42 return self.decode(z, c), mu, logvar
<ipython-input-68-127374cfac97> in decode(self, z, c)
35 def decode(self, z, c):
36 concat_input = torch.stack([z, c], 1)
---> 37 return self.fc5(F.selu(self.fc4(F.selu(self.fc3(concat_input)))))
38
39 def forward(self, x, c):
~\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~\anaconda3\lib\site-packages\torch\nn\modules\linear.py in forward(self, input)
94
95 def forward(self, input: Tensor) -> Tensor:
---> 96 return F.linear(input, self.weight, self.bias)
97
98 def extra_repr(self) -> str:
~\anaconda3\lib\site-packages\torch\nn\functional.py in linear(input, weight, bias)
1845 if has_torch_function_variadic(input, weight):
1846 return handle_torch_function(linear, (input, weight), input, weight, bias=bias)
-> 1847 return torch._C._nn.linear(input, weight, bias)
1848
1849
RuntimeError: mat1 and mat2 shapes cannot be multiplied (4096x8 and 16x8)
I’m not sure how the concatenation or stacking would work in this case.
Could you explain how the single value should be concatenated to the tensor of [2048, 20]?
The second error is raised due to a shape mismatch in a linear layer, so check the feature dimension in the input activation and make sure it matches the in_features of the linear layer.
I wanted to include the decoder to condition(cond_dim) و Is there another way to do this?
It would depend on your idea what the concatenation would mean.
Right now you are using a 2D tensor in the shape [2048, 20] and are trying to concatenate a single value to it, which won’t work.
Think about this use case as having an image and trying to “concatenate” a single value (pixel) to it.
You could of course repeat the single pixel value and create a row, column, or entire image plane, and concatenate these tensors, but I don’t know what your overall use case expects.
@ptrblck I changed the cond_dim dimension to [2048,1]:
cond_dim = cond_dim.repeat(2048,1)
actually just as an input for decode in sample function because for other part for example
cvae = CVAE(c_dim=cond_dim1).to(device)
I couldn’t add 2D tensor. but The following error appeared after running:
---> 28 samples_model = cvae.sample()
29 samples_gt = gen_batch(2048)
30 kde_skl = KernelDensity(kernel='gaussian', bandwidth=0.2)
<ipython-input-120-59830598ea49> in sample(self, n)
32 # sample = cvae.decode(z, c)
33 sample = torch.randn(n, K).to(device)
---> 34 out = cvae.decode(sample, cond_dim)
35
36 return out.cpu().detach().numpy()
<ipython-input-120-59830598ea49> in decode(self, z, c)
39 def decode(self, z, c):
40 concat_input = torch.cat([z, c], 1)
---> 41 return self.fc5(F.selu(self.fc4(F.selu(self.fc3(concat_input)))))
42
43 def forward(self, x, c):
~\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~\anaconda3\lib\site-packages\torch\nn\modules\linear.py in forward(self, input)
94
95 def forward(self, input: Tensor) -> Tensor:
---> 96 return F.linear(input, self.weight, self.bias)
97
98 def extra_repr(self) -> str:
~\anaconda3\lib\site-packages\torch\nn\functional.py in linear(input, weight, bias)
1845 if has_torch_function_variadic(input, weight):
1846 return handle_torch_function(linear, (input, weight), input, weight, bias=bias)
-> 1847 return torch._C._nn.linear(input, weight, bias)
1848
1849
RuntimeError: mat1 and mat2 shapes cannot be multiplied (2048x21 and 28x20)
I really stuck to this, could you please help me to go further. thanks in advance
One of the linear layers (self.fc3, self.fc4, or self.fc5) raises the shape mismatch error, so you would need to make sure the feature dimension of the input activation matches the in_features of the corresponding linear layer. My best guess is that concat_input's feature dim doesn’t fir into self.fc3.
Thank you for your reply. it seems that the conditioning itself will not help much with multi-modality but it is rather about the specific structure of the implemented VAE. So I used MNIST dataset instead of the previous dataset. But when all the dimensions of decoder and encoder part were K I got this error:
<ipython-input-96-ac87136b4d41> in train(epoch)
13 data, cond = data.to(device), one_hot(cond, cond_dim).to(device)
14 optimizer.zero_grad()
---> 15 recon_batch, mu, logvar = cvae(data, cond)
16 # print("mu", mu)
17 # print("logvar", logvar)
~\anaconda3\lib\site-packages\torch\nn\modules\module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
<ipython-input-88-258e170a951c> in forward(self, x, c)
42
43 def forward(self, x, c):
---> 44 mu, logvar = self.encode(x.view(-1, 2), c)
45 z = self.reparameterize(mu, logvar)
46 return self.decode(z, c), mu, logvar
<ipython-input-88-258e170a951c> in encode(self, x, c)
14
15 def encode(self, x, c):
---> 16 concat_input = torch.cat([x, c], 1)
17 h1 = F.selu(self.fc1(F.selu(self.fc0(concat_input))))
18 return self.fc21(h1), self.fc22(h1)
RuntimeError: torch.cat(): Sizes of tensors must match except in dimension 1. Got 39200 and 100 in dimension 0 (The offending index is 1)
and it just works when the dimensions were similar to the following code:
def __init__(self, c_dim):
super(CVAE, self).__init__()
# encoder part
self.fc0 = nn.Linear(784 + c_dim, 512)
self.fc1 = nn.Linear(512, 256)
self.fc21 = nn.Linear(256, 2)
self.fc22 = nn.Linear(256, 2)
# decoder part
self.fc3 = nn.Linear(2 + c_dim, 256)
self.fc4 = nn.Linear(256, 512)
self.fc5 = nn.Linear(512, 784)
I think you are again hitting the issue of trying to concatenate two tensors with a different shape as described e.g. in this post. This time you are trying to concatenate x and c in dim1 while dim0 shows the shape mismatch.