I saw topics on [Should we set non_blocking to True? - PyTorch Forums]
. I read answers and i saw post [[How to Overlap Data Transfers in CUDA C/C++ | NVIDIA Technical Blog]] How to Overlap Data Transfers in CUDA C/C++ | NVIDIA Technical Blog (add https:// i’m new user so , i can’t add another link)
I wonder if my understanding is correct .
Following code is from ptrblck’s answers.
for data, target in loader:
# Overlapping transfer if pinned memory
data = data.to('cuda:0', non_blocking=True)
target = target.to('cuda:0', non_blocking=True)
# The following code will be called asynchronously,
# such that the kernel will be launched and returns control
# to the CPU thread before the kernel has actually begun executing
output = model(data) # has to wait for data to be pushed onto device (synch point)
loss = criterion(output, target)
loss.backward()
optimizer.step()
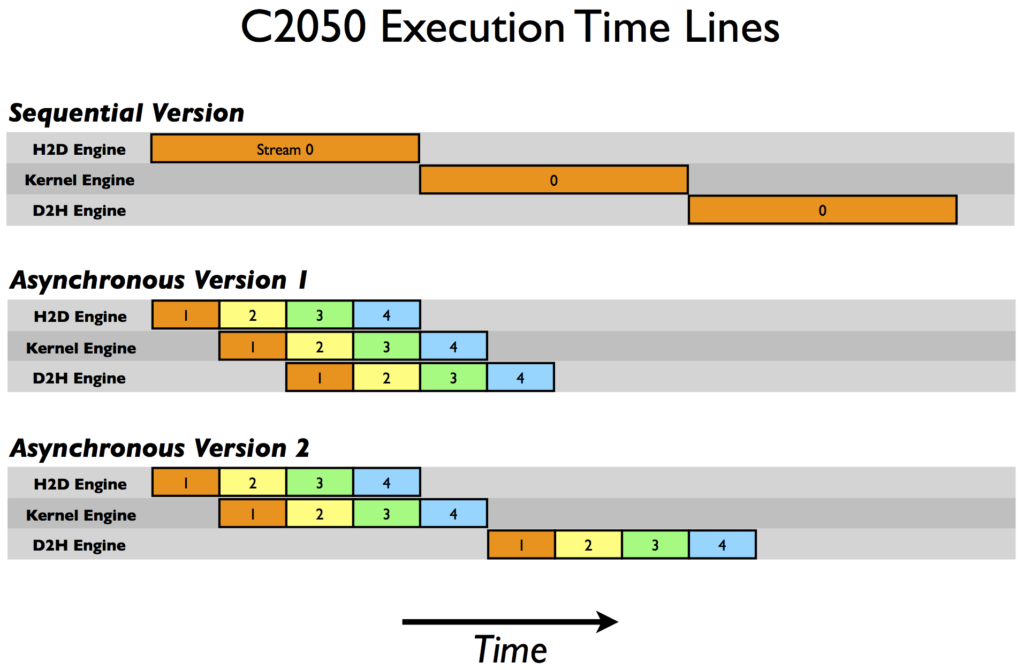
i assume that async data transfer to gpu is available . Also, i use single gpu.
Q. Is the data splitted into small chunk and operation executed like async version 2 in picture?
From what I understand , batch_data is splitted in small chunk (nvidia’s async transfer). Then , kernel(in this code, output = model(data) ,)loss = criterion(output, target) is executed . loss.backward() optimizer.step()` i think backward is computed for batch_data if there is a batchnormalization . So ,In my opinion, backward should be sync point .
Also, I thinnk that optimize.step must be blocked to main process. Because, model must compute output after model parameter’s update.
What i undersatnd is correct?
I have another question
Q .
When GPu execute ouput calculate, loss calculate , backward , optimize by gpu , Cpu execute data transfer to gpu parallely( data = data.to('cuda:0', non_blocking=True) target = target.to('cuda:0', non_blocking=True) ) ?
In above picture, there are kernel engine and h2d engine. From what i understand, Kernel engine and h2d engine are separate. h2d engine just transfer data to device regardless of kernel engine. Kernel Engine wait until optimization step finish. Then , If data has been transferred to device already, Kernel Engine computes model ouputs. In Conclusion , DataLoaderPart(data transfer to gpu) and ModelComputationpart(ouput,loss,backward,optimize) are executed paralelly , but model output can be computed when data has been transferred to device already.
Thank you for seeing my topic