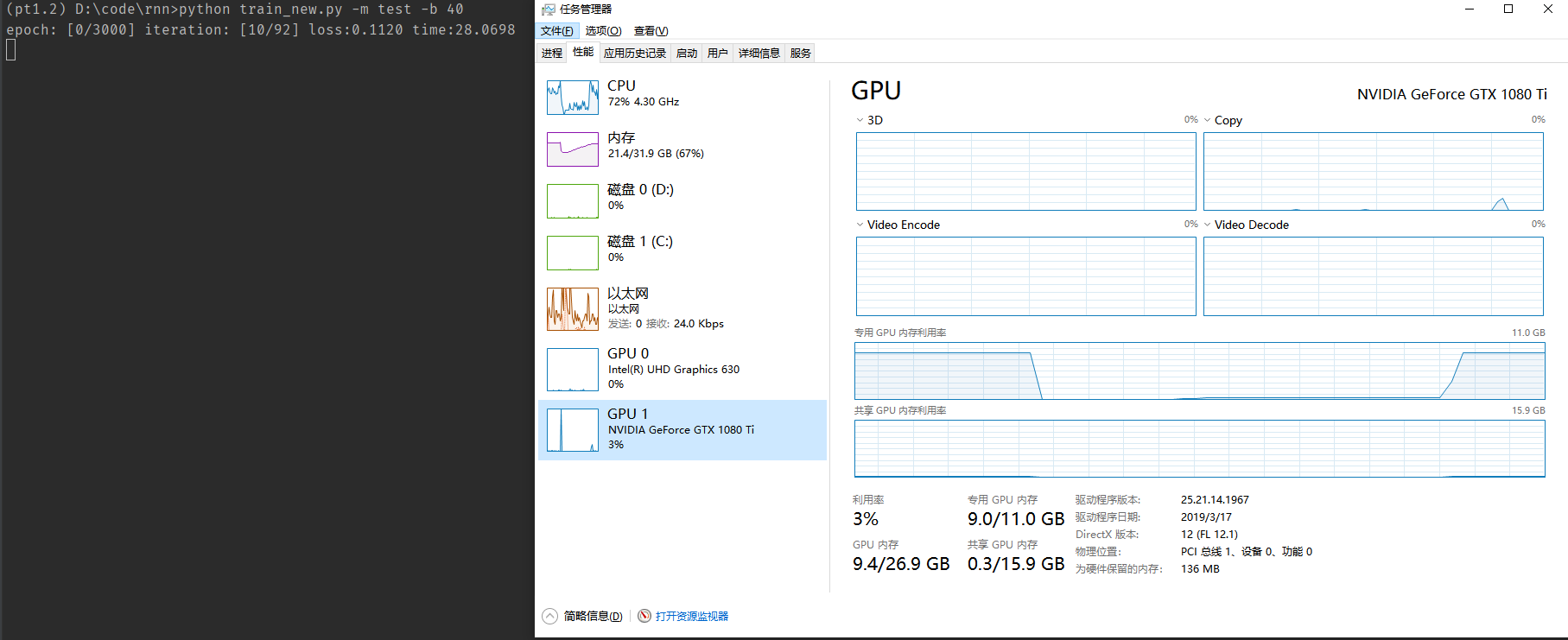
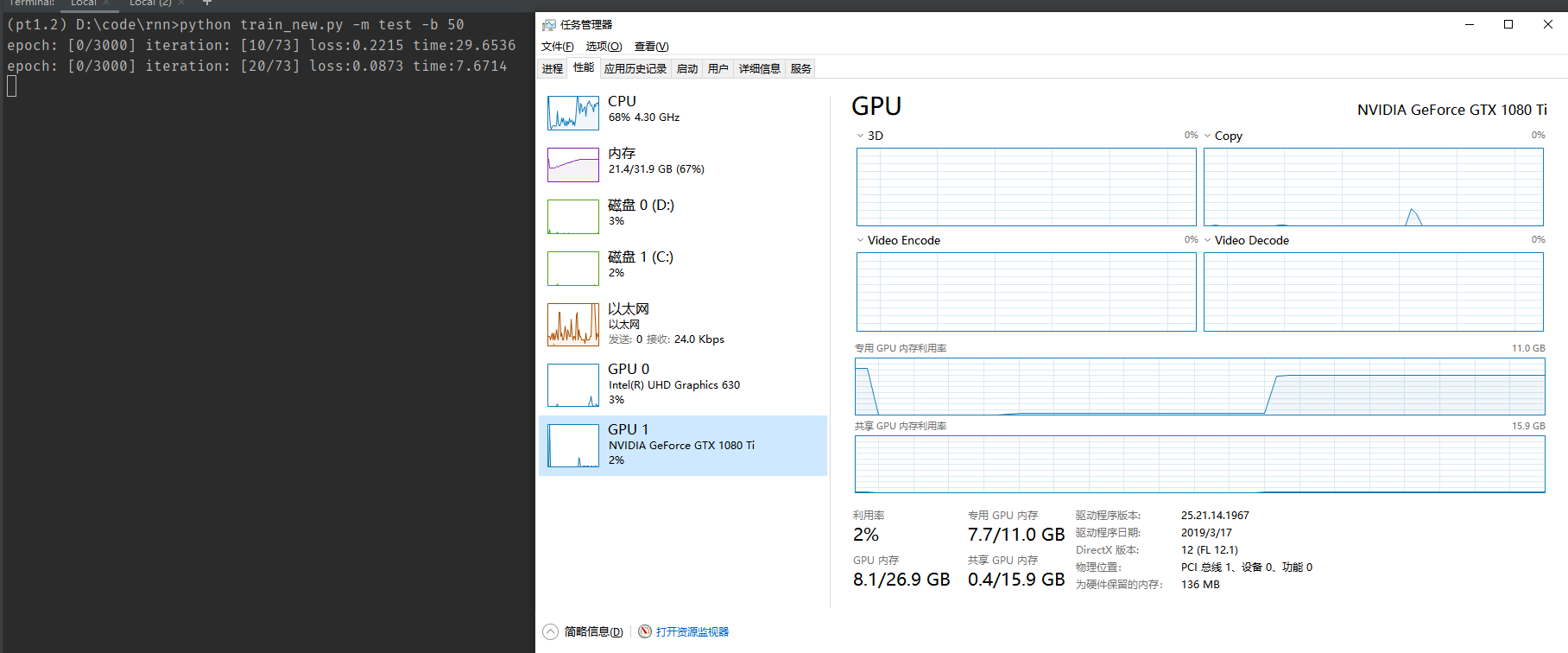
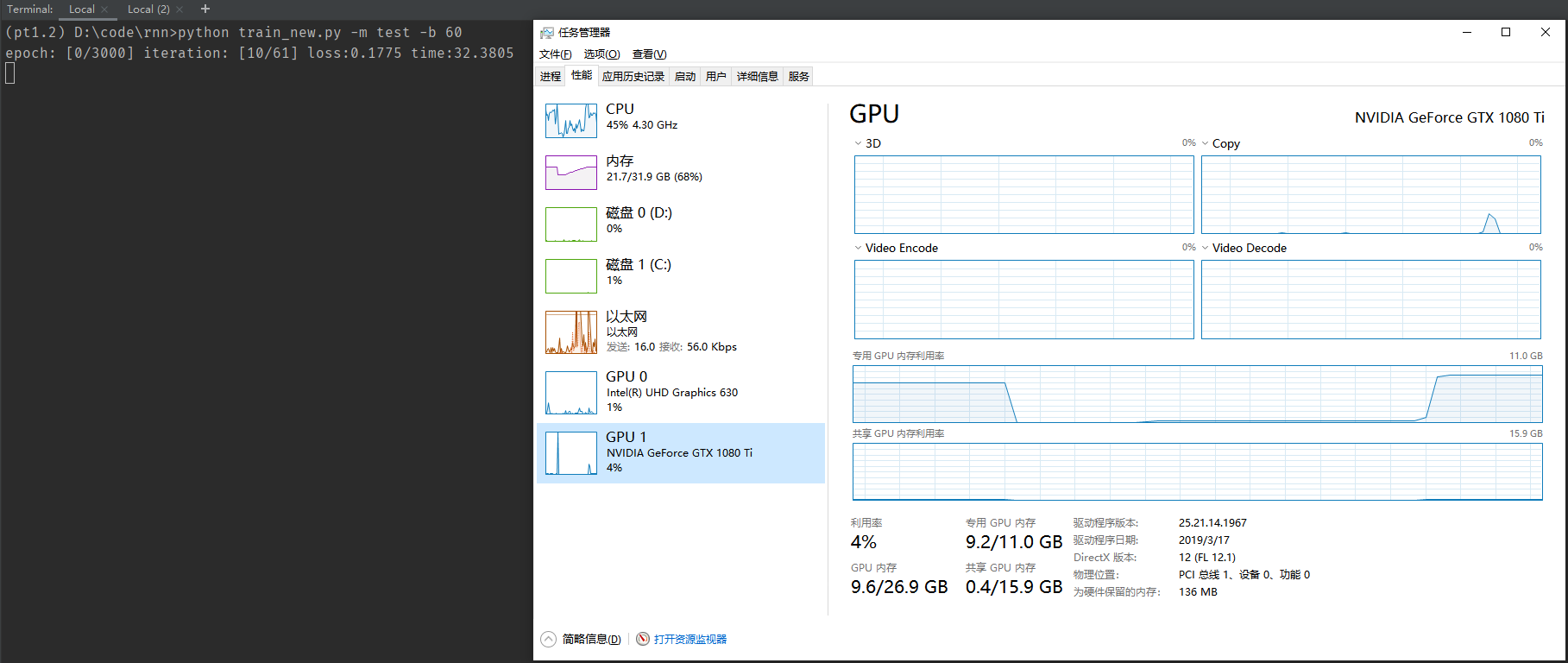
As you can see when the batch size is 40 the Memory-Usage of GPU is about 9.0GB, when I increase the batch size to 50, the Memory-Usage of GPU decrease to 7.7GB. And I continued to increase the batch size to 60, and it increase to 9.2GB. Why the Memory-Usage of GPU was so high.According to the common sense, it should be lower than 7.7GB.
The displayed memory usage should show the CUDA context + the actual memory used to store tensors + cached memory + other applications.
Try to check the memory using torch.cuda.memory_allocated() and torch.cuda.memory_cached().
I add the flowing sentence in my code
if (iteration+1)%10 == 0:
stop = time.time()
print("epoch: [%d/%d]"%(epoch,EPOCHS), "iteration: [%d/%d]"%(iteration + 1,len(train_dataset)//BATCH_SIZE), "loss:%.4f" % loss.item(),
'time:%.4f' % (stop - start))
print("torch.cuda.memory_allocated: %fGB"%(torch.cuda.memory_allocated()/1024/1024/1024))
print("torch.cuda.memory_cached: %fGB"%(torch.cuda.memory_cached()/1024/1024/1024))
start = time.time()
And the output in the terminal as follow:
(pt1.2) D:\code\rnn>python train_new.py -m test -b 40
epoch: [0/3000] iteration: [10/92] loss:0.1948 time:28.8928
torch.cuda.memory_allocated: 0.141236GB
torch.cuda.memory_cached: 8.539062GB
epoch: [0/3000] iteration: [20/92] loss:0.0986 time:6.5122
torch.cuda.memory_allocated: 0.141236GB
torch.cuda.memory_cached: 8.539062GB
(pt1.2) D:\code\rnn>python train_new.py -m test -b 50
epoch: [0/3000] iteration: [10/73] loss:0.1436 time:29.8940
torch.cuda.memory_allocated: 0.144663GB
torch.cuda.memory_cached: 7.197266GB
epoch: [0/3000] iteration: [20/73] loss:0.0644 time:7.6573
torch.cuda.memory_allocated: 0.144663GB
torch.cuda.memory_cached: 7.197266GB
(pt1.2) D:\code\rnn>python train_new.py -m test -b 60
epoch: [0/3000] iteration: [10/61] loss:0.1918 time:31.1637
torch.cuda.memory_allocated: 0.151530GB
torch.cuda.memory_cached: 8.666016GB
epoch: [0/3000] iteration: [20/61] loss:0.0936 time:8.8493
torch.cuda.memory_allocated: 0.151408GB
torch.cuda.memory_cached: 8.666016GB
Since the allocated memory increases with a higher batch size, it looks fine. 
yes, but I wonder why the memory cached of b40 will be larger than b50. It will be difficult for me to set the proper batch size.
The cache size might vary e.g. due to cudnn benchmarking and shouldn’t yield an out of memory error, if I’m not mistaken. Are you running out of memory using a smaller batch size?
hello, when batch size increases only by 1(from 4 to 5), why my pyptorch allocated memory still stays the same but the cached memory inscreses?
| batch size | TI allocated | TI cached |
|---|---|---|
| 4 | 4674.74 MB | 25890.00 MB |
| 5 | 4674.74 MB | 31212.00 MB |
This should not be the case since already the input tensor would use more memory, so I guess the increase might be too small and is truncated in your MB view.
Hi, I’m fine-tuning stable diffusion1-5, and tested these three fine-tune ways, TI, LoRA , LoRA--CTI. Since the model is so big, I do not think the increse is small. I think the computation graph should increse just as the TI cached_memory ‘with batch size incresed by one, memory increases about 5G’.
So I’m so confused of this issue. Is it possible that pytorch will distribute more memory for the matrix with sufficent gpu memory in your compute? Thanks for your reply!
| batch size | TI allocated | TI cached | LoRA allocated +CTI | LoRA cached+CTI | LoRA allocated -CTI | LoRA cached-CTI |
|---|---|---|---|---|---|---|
| 4 | 4674.74 MB | 25890.00 MB | 4866.56 MB | 25962.00 MB | 4576.99 MB | 25960.00 MB |
| 5 | 4674.74 MB | 31212.00 MB | 4866.56 MB | 17792.00 MB | 4576.99 MB | 17492.00 MB |
I don’t know what this means, but please refer to my previous post about workspaces used in e.g. cudnn.benchmark.
It also still doesn’t make sense that the allocated memory stays the same so I guess you might not b emeasuring the inputs and created intermediates.
Ok, thank you. I’ll try it later!