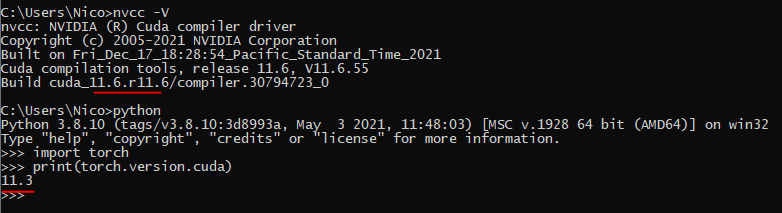
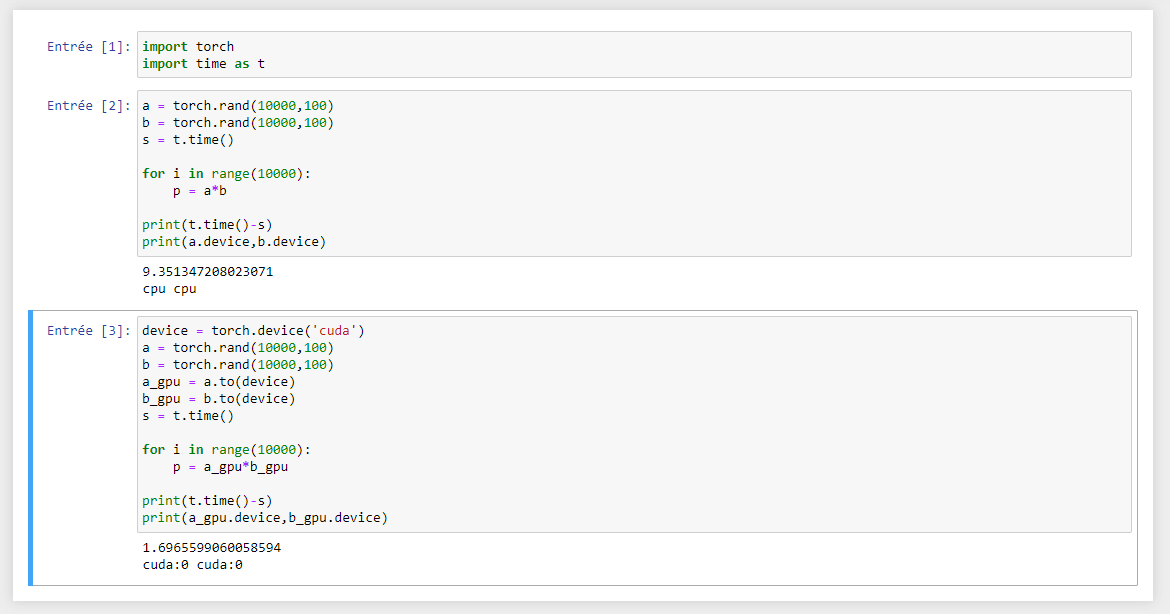
I just did a new test and in fact my cuda/gpu works as shown on the picture:
But I don’t know why my code here is very very slow, when you run it you can see that it shows me that my learning loop is at about 7it/s with GPU and 3-4it/s with CPU, but two days ago with the same code I was reaching 35it/s, I tested on a friend’s computer (with a very similar graphics card) and it also has 35s/it. I checked my NVIDIA Cuda driver and my version of cuda toolkit, and they have no problem, but I don’t know why in my code here “that only on my computer” it is slow.
Here is my code:
If you want the data also to test everything is here, (note I am not the person who wrote this code, it is my teacher) :
https://filesender.renater.fr/?s=download&token=517e4ce7-3316-4774-b622-4ee49e85ff39
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
# from torch.autograd import Variable
import torchvision.transforms as transforms
import torchvision.datasets as dset
import torchvision.utils as vutils
from PIL import ImageFile
# import os
from tqdm import tqdm
learning_rate = 0.01
momentum = 0.5
batch_size_train = 40
batch_size_test = 500
# Dataloader class and function
ImageFile.LOAD_TRUNCATED_IMAGES = True
class Data:
def __init__(self, dataset_train, dataset_train_original, dataloader_train,
dataset_test, dataset_test_original, dataloader_test,
batch_size_train, batch_size_test):
self.train = dataset_train
self.train_original = dataset_train_original
self.loader_train = dataloader_train
self.num_train_samples = len(dataset_train)
self.test = dataset_test
self.test_original = dataset_test_original
self.loader_test = dataloader_test
self.num_test_samples = len(dataset_test)
self.batch_size_train = batch_size_train
self.batch_size_test = batch_size_test
def loadImgs(des_dir="./data/", img_size=100, batch_size_train=40, batch_size_test=100):
dataset_train = dset.ImageFolder(root=des_dir + "train/",
transform=transforms.Compose([
transforms.Resize(img_size),
transforms.RandomCrop(75, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]))
dataset_train_original = dset.ImageFolder(root=des_dir + "train/",
transform=transforms.Compose([
transforms.Resize(img_size),
transforms.ToTensor(),
]))
dataset_test = dset.ImageFolder(root=des_dir + "test/",
transform=transforms.Compose([
transforms.Resize(img_size),
transforms.RandomCrop(75, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
]))
dataset_test_original = dset.ImageFolder(root=des_dir + "test/",
transform=transforms.Compose([
transforms.Resize(img_size),
transforms.ToTensor(),
]))
dataloader_train = torch.utils.data.DataLoader(dataset_train, batch_size=batch_size_train, shuffle=True)
dataloader_test = torch.utils.data.DataLoader(dataset_test, batch_size=batch_size_test, shuffle=True)
data = Data(dataset_train, dataset_train_original, dataloader_train,
dataset_test, dataset_test_original, dataloader_test,
batch_size_train, batch_size_test)
return data
# evaluation on a batch of test data:
def evaluate(model, data):
batch_enum = enumerate(data.loader_test)
batch_idx, (testdata, testtargets) = next(batch_enum)
testdata = testdata.to(device)
testtargets = testtargets.to(device)
model = model.eval()
oupt = torch.argmax(model(testdata), dim=1)
t = torch.sum(oupt == testtargets)
result = t * 100.0 / len(testtargets)
model = model.train()
print(f"{t} correct on {len(testtargets)} ({result.item()} %)")
return result.item()
# iteratively train on batches for one epoch:
def train_epoch(model, optimizer, data):
batch_enum = enumerate(data.loader_train)
i_count = 0
iterations = data.num_train_samples // data.batch_size_train
for batch_idx, (dt, targets) in tqdm(batch_enum):
i_count = i_count+1
outputs = model(dt.to(device))
loss = F.cross_entropy(outputs, targets.to(device))
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i_count == iterations:
break
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.25)
self.dropout3 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(((((75-2)//2-2)//2)**2)*64, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 2)
def forward(self, x):
x = F.relu(self.conv1(x.view(-1, 3, 75, 75)))
x = self.dropout1(F.max_pool2d(x, 2))
x = F.relu(self.conv2(x))
x = self.dropout2(F.max_pool2d(x, 2))
x = torch.flatten(x, 1)
x = self.dropout3(F.relu(self.fc1(x)))
x = self.fc2(x)
x = self.fc3(x)
return x
data = loadImgs(batch_size_train=batch_size_train, batch_size_test=batch_size_test)
net = Net().to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=learning_rate, momentum=momentum)
# net.load_state_dict(torch.load('./data/model_TP.pt'))
# evaluate(net, data)
num_epochs = 1
for j in range(num_epochs):
print(f"epoch {j} / {num_epochs}")
train_epoch(net, optimizer, data)
evaluate(net, data)
torch.save(net.state_dict(), './data/model_TP.pt')