Hi.
It’s commonly said that, if one wants to set torch.backends.cudnn.benchmark=True so as to speed up pytorch computation, he or she should always ensure that the input size of batches stay constants.
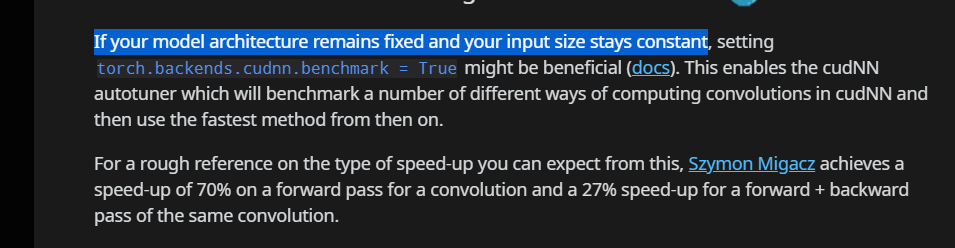
This arouse me a question. As we know, the size of a batch output from the DataLoader dose not always equal to the batch_size parameter we pass to it, because the dataset size is not always divisible by the batch_size. So we got a drop_last parameter in DataLoader to determine whether to drop the last incomplete batch.
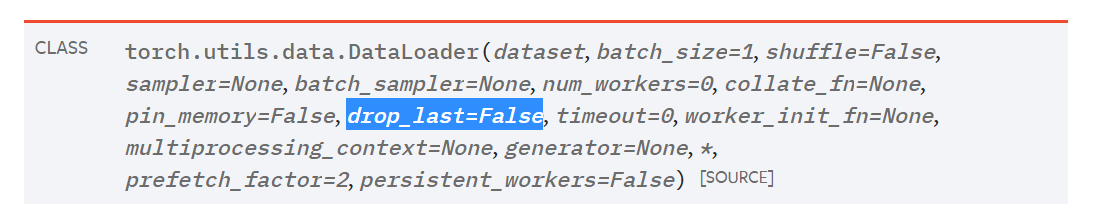
The default value of drop_last is False, meaning that the last batch’s size might be smaller, which violates the precondition for torch.backends.cudnn.benchmark=True.
So, should I always set drop_last=True when I want to set torch.backends.cudnn.benchmark=True?
Thanks!