My network model is quite large. But I want to know if it fits entirely in gpu memory. How can I do it?
Push the model to the device via model.to('cuda') and check the memory usage via nvidia-smi.
If the model doesn’t fit, PyTorch will raise an error.
Also, since the intermediate activations will use additional memory during training, you might run a dummy forward and backward pass and check the memory usage via:
torch.cuda.memory_allocated()
torch.cuda.max_memory_allocated()
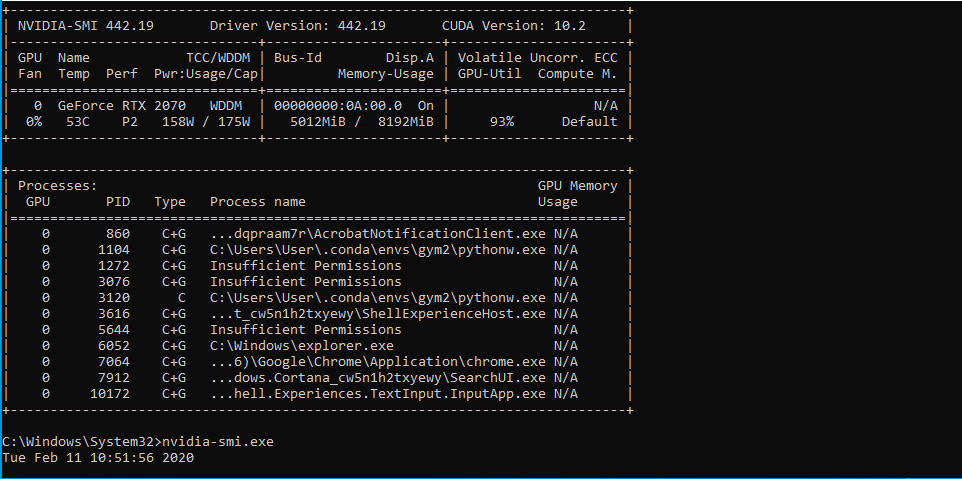
The easiest is to put the entire model onto GPU and pass the data with batch size set to 1. If it doesn’t fit, then try considering lowering down your parameters by reducing the number of layers or removing any redundant components that might be taking RAM. From the screenshot, I see that the model fits, you need to lower your batch size to the minimum to find the threshold value.
The model is placed at batch size = 50, 100, 200, 500 :). But the working time for the era does not change. With batch 50, the run time is 19 seconds; with batch 500, the run time is 18.7 seconds. It should be?
As far as I understand, there is a memory inside the video card. My video card is 8GB. There are also processor cores. It seems to me that cores are responsible for parallel computing, the more there are, the faster the calculation. And the memory is just a buffer.
For me, the most incomprehensible question is whether there will be an acceleration of work if I use not 1 GPU, but 4? Maybe someone has 4 GPUs, can I give my model to check the speed of work on 1 GPU and on 4?
my model size is 355mb i have predication time is 30sec so i want to reduce predication time please give any idea