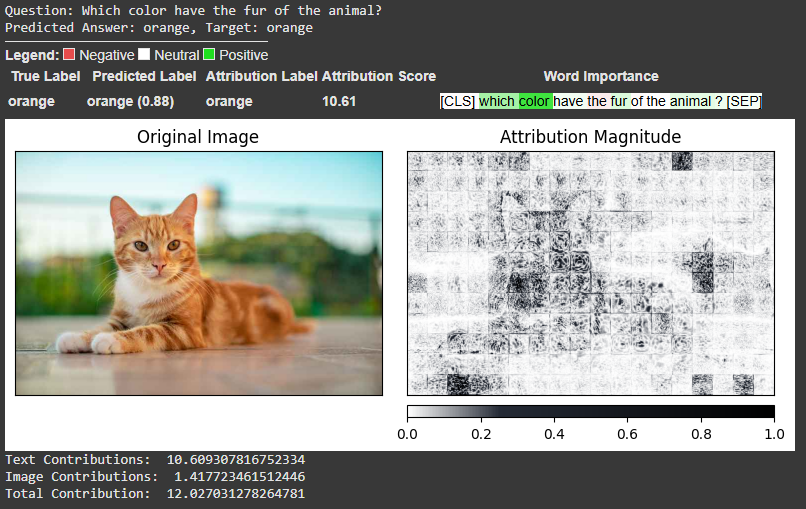
Hi there,
I would like to use IG for Image and Text to display the results of VLM models such as LLava-OneVision or Phi-3.5-Vision-instruct on a VQA task with multiple images.
I have already created a Google Colab notebook for a simple model from Transformers. However, I cannot pass the pixel_values and input_embeds together when using the llava model. Do you have any ideas how to overcome this?
Also, the results for the dandelin/vilt-b32-finetuned-vqa model don’t look quite right somehow.