I’m stuck in error situation. I have posted some questions for this model.
So, I changed model a lot. But, Every time I make a new edit, I get a new error.
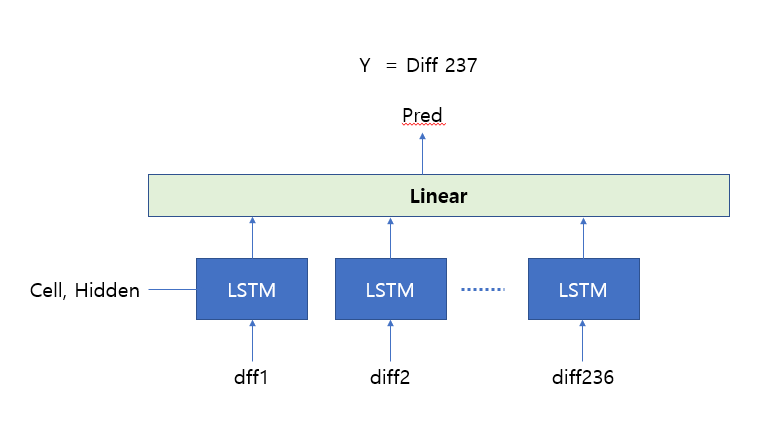
The input is scaled from 0 to 1, and an error occurs when the value of [236,1] is output through LSTM and Linear. The input data is 236 difference values in the price data. For example, Day2 - Day1 is the data of input 1.
from pandas import Series
from pandas import DataFrame
from pandas import concat
from pandas import read_csv
from pandas import datetime
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from math import sqrt
from matplotlib import pyplot
import numpy
import torch.nn as nn
import torch
from torch.autograd import Variable
def timeseries_to_supervised(data, lag=1):
#label 값을 만드는 함수
df = DataFrame(data)
#columns는 label 값으로 data를 한개씩 내린 결과값을 갖게된다 shift함수사용
## x1 x2
##0 206 nan
##1 226 206
##2 245 226
##3 265 245
##4 283 265
##5 nan 283
columns = [df.shift(i) for i in range(1, lag+1)]
#concat : axis = 1이면 columns를 구성
df = concat(columns, axis = 1)
#nan 값을 0 으로 바꾼다
df.fillna(0, inplace = True)
return df
def difference(dataset, interval=1):
diff = list()
for i in range(interval, len(dataset)):
value = dataset[i] - dataset[i - interval]
diff.append(value)
#One-dimensional ndarray with axis labels를 만드는 Series(Diff)
return Series(diff)
# scale train and test data to [-1, 1]
def scale(train, test):
# fit scaler
scaler = MinMaxScaler(feature_range=(0, 1))
scaler = scaler.fit(train)
# transform train
print("Train Data Shape" , train.shape)
train = train.reshape(train.shape[0], train.shape[1])
train_scaled = scaler.transform(train)
# transform test
test = test.reshape(test.shape[0], test.shape[1])
test_scaled = scaler.transform(test)
return scaler, train_scaled, test_scaled
def invert_scale(scaler, X, value):
new_row = [x for x in X] + [value]
array = numpy.array(new_row)
array = array.reshape(1, len(array))
inverted = scaler.inverse_transform(array)
return inverted[0, -1]
class model(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(model, self).__init__()
self.input_size =input_size
self.hidden_size = hidden_size
self. num_layers = num_layers
self.rnn = nn.LSTM(input_size, hidden_size, num_layers)
self.dense = nn.Linear(hidden_size,1)
def forward(self, input, hidden, cell):
out, hidden = self.rnn(input, (hidden, cell))
output = self.dense(out)
return output
if __name__ == "__main__":
# squeeze = True이면 index 열을 제외한 하나의 열만을 가져올 때 해당 열을 Series로 만들어서 반환해준다
series = read_csv('C:/Users/asdfw/Desktop/ICC_Example/data/BTCUSD.csv', header=0, parse_dates=[0], index_col=0, squeeze=True)
# transform data to be stationary
raw_values = series.values
diff_values = difference(raw_values, 1)
# transform data to be supervised learning
supervised = timeseries_to_supervised(diff_values, 1)
supervised_values = supervised.values
split = int(395*0.6)
train, test = supervised_values[0:split], supervised_values[split:]
#print(train)
# transform the scale of the data
scaler, train_scaled, test_scaled = scale(train, test)
#------------scaled된 data를 토대로 모델을 훈련시킨다--------------------
input_size = 1
hidden_size = 59
num_layers = 1
batch_size = 1
seq_len = len(train) - 1
rnn = model(input_size, hidden_size, num_layers)
optimizer = torch.optim.Adam(rnn.parameters(), lr = 0.0001)
#--------rnn(input) predict 수행---------
#Series 데이터인 train은 numpy의 ndarray이므로 torch tensor로 바꾸어 주어야한다
X = Variable(torch.from_numpy(train[:-1,:]).float())
y = Variable(torch.from_numpy(train[-1,:]))
X = X.view(-1, batch_size, input_size)
for i in range(0, 10):
hidden = Variable(torch.zeros(num_layers,batch_size,hidden_size))
cell = Variable(torch.zeros(num_layers,batch_size,hidden_size))
print('X shape / Y shape', X.size(), y.size())
predict = rnn(X, hidden, cell)
loss = nn.CrossEntropyLoss()
print('Predict size is ', predict.size())
predict = predict.view(-1, 1)
y = y.long()
err = loss(predict, y.view(-1))
err.backward()
optimizer.step()
print('Loss Is :::', loss)
This is my source code. And I got an error like this.

How to solve that problem…?
I don’t know anything to solve it.
Maybe someone could complete my code based on it?
I want to go on studying the finished model.