I am following an image captioning tutorial here and am struggling to comprehend a particular line of code. As a visual, I am trying to build the following architecture:
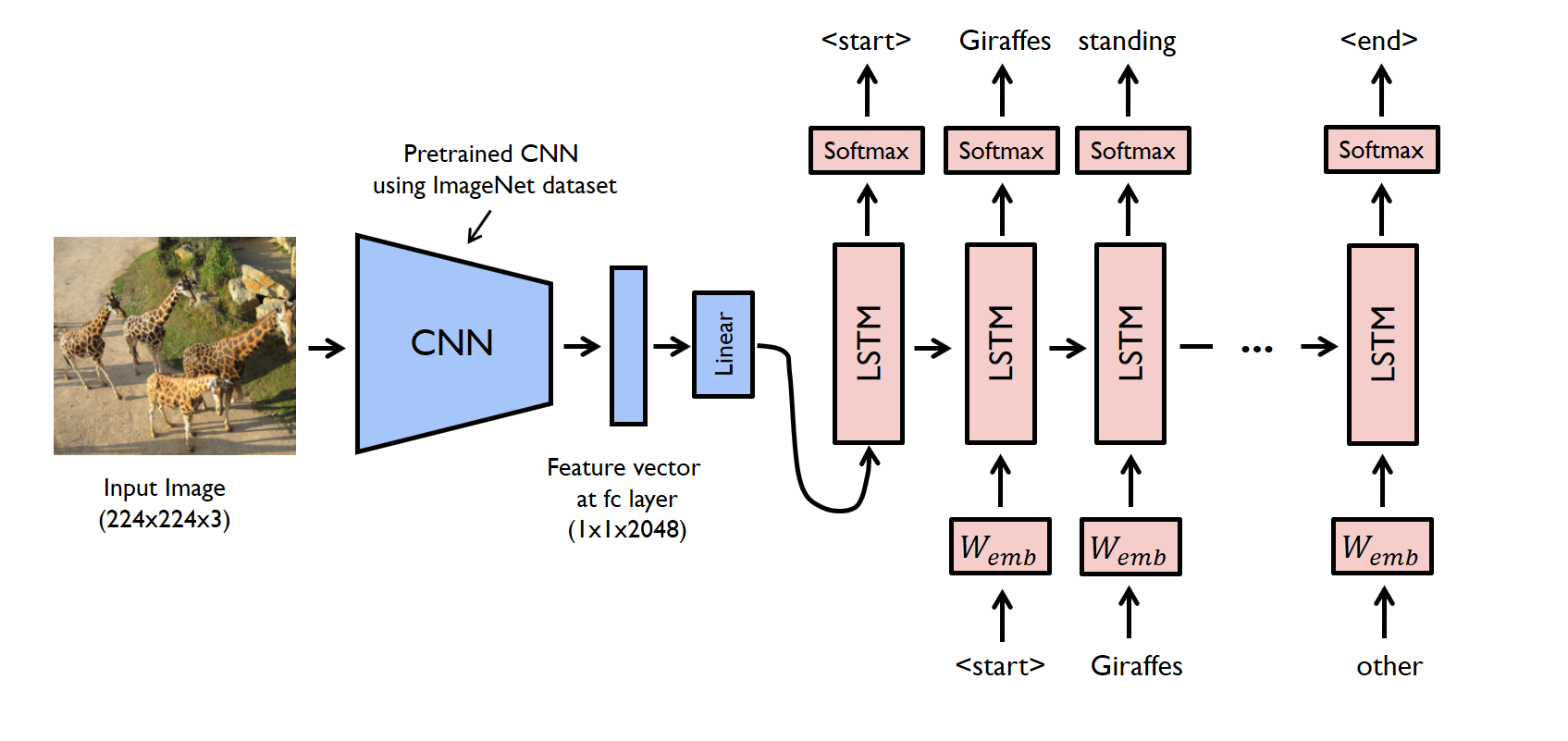
In reference to the code here, I don’t understand why the last line in this snippet is possible (lines 37-39):
embeddings = self.embed(captions)
embeddings = torch.cat((features.unsqueeze(1), embeddings), 1)
packed = pack_padded_sequence(embeddings, lengths, batch_first=True)
Specifically, if lengths corresponds to the length of each respective caption, why is it that we can
concatenate features.unsqueeze(1) to our embeddings without adding an additional entry to lengths?