I am implementing a ResNet + Transformer model to do image caption. Gist of code is as follows:
class Ensemble(nn.Module):
def __init__(self):
super(Ensemble, self).__init__()
# outputs spatial features before avg. pooling
self.resnet = CustomResNet(pretrained=True)
# do not fine-tune
for param in self.resnet.parameters():
param.requires_grad = False
# transformer that takes image features as inputs
self.transformer = CustomTransformer()
# num_channel is the number of channels of the image features from last resnet layer
# hidden_dim is the hidden dimension used across transformer
self.linear = nn.Linear(num_channel, hidden_dim)
self.relu = nn.ReLU()
def forward(self, inputs, outputs):
# B(batch) x W*H(spatial span) x num_channel
activations = self.resnet(inputs)
# B x W*H x hidden_dim
activations = self.linear(activations)
activations = self.relu(activations)
# B x N_out x vocab_size
out = self.transformer(activations, outputs)
The overall idea is that I take spatial features from a pre-trained resnet model (B x W*H x C) and use them as inputs to a transformer model. Similar idea can be found in this paper and repo.
During training, I realize that the model is not picking up information from the image side and is generating outputs based entirely on the given caption. It is purely using the prior it learned from all the captions to generate the next word, instead of looking at the image. To validate this, I tried using activations = torch.zeros_like(activations) as inputs to transformer, and obtained a similar performance to using original activations.
To investigate, I generated a plot of gradients at different layers of the model.
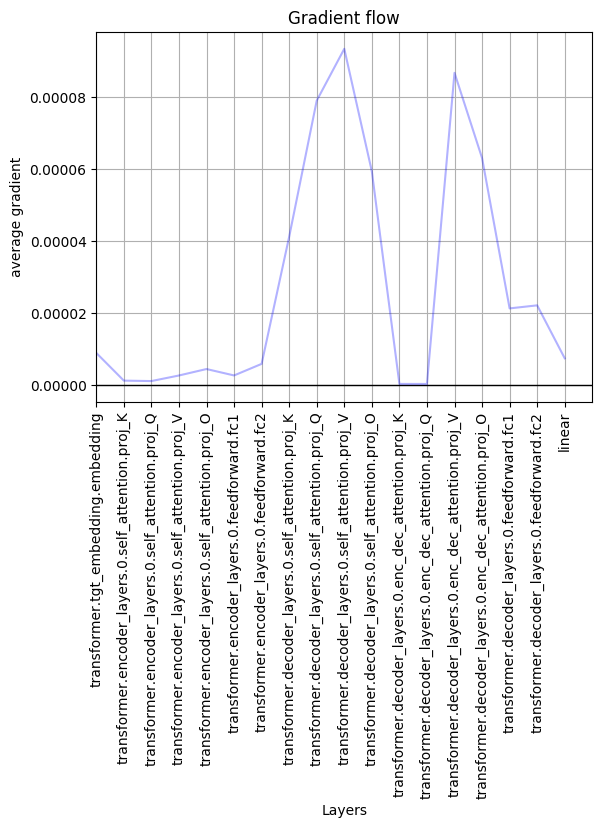
As expected, the gradients at encoder’s self attention are quickly diminishing towards zero(model is not learning from the image features, which are encoder features), while gradients at decoder’s self attention are kept very well(as the model is learning everything based on the output captions, which come from decoder).
The problems of diminishing gradients could be alleviated by gradient clipping, batch/layer normalization and proper weight initialization, which I already integrated with the model. However the issue persists. I am wondering has anyone encountered a similar issue before? Is the problem more likely to be due to improper training parameters, or potentially incorrect model implementation? Is there a way to force the model to base its caption output on the image features? Really appreciate any feedback or pointers!