Hello @ptrblck,
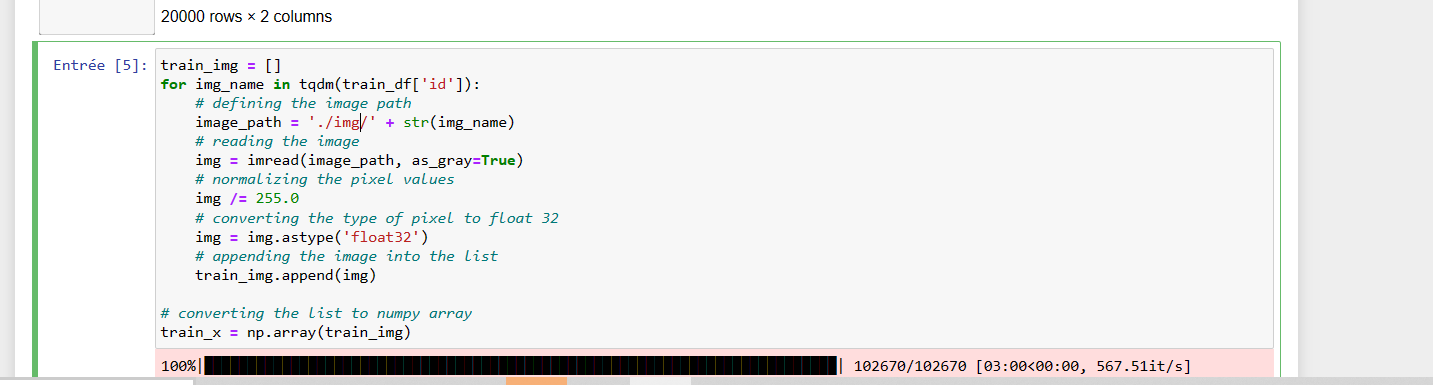
In fact, i want to concat image pixels (train_x) and their labels(train_y). Then I want to convert to tensor.
I don’t know how to do ?
Thank You
Hello @ptrblck,
In fact, i want to concat image pixels (train_x) and their labels(train_y). Then I want to convert to tensor.
I don’t know how to do ?
Thank You
Some more details about your objective might help.
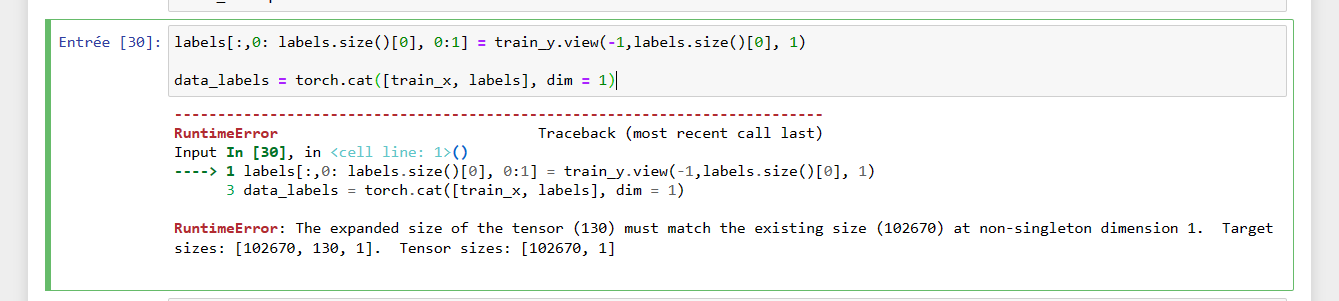
In order to concat 2 tensors, they need to be the same size, except in the dim being concatenated. You could do:
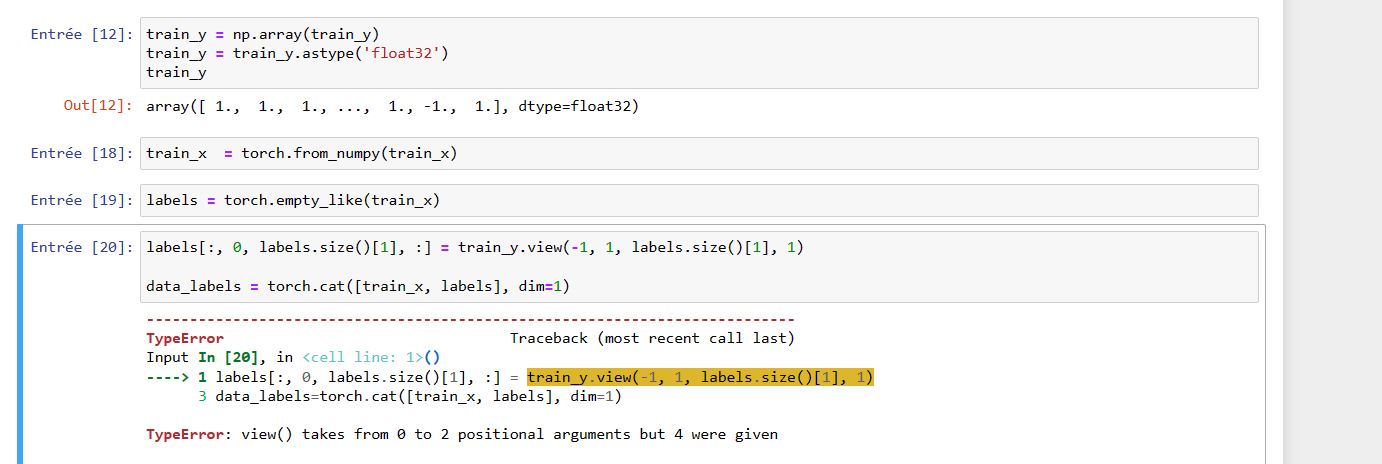
labels = torch.empty_like(train_x)
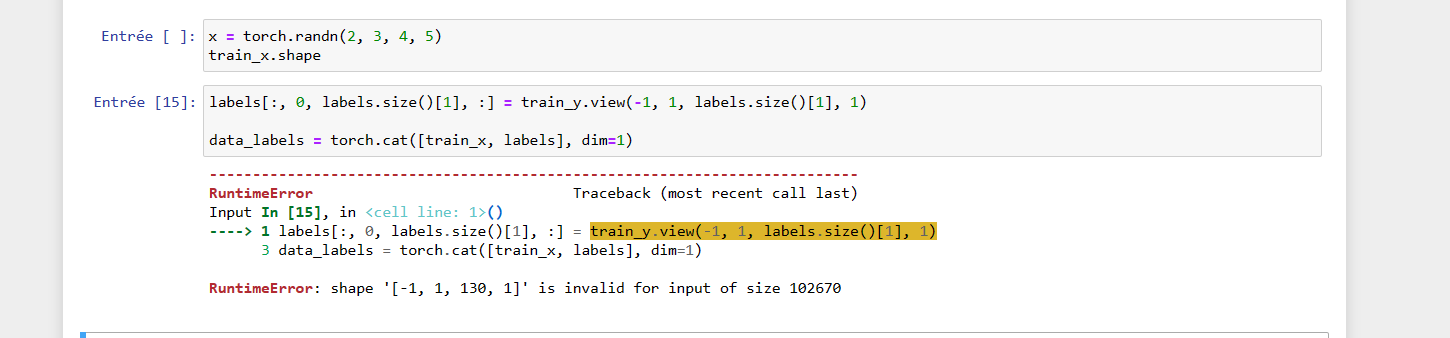
labels[:, 0, labels.size()[1], :] = train_y.view(-1, 1, labels.size()[1], 1)
data_labels=torch.cat([train_x, labels], dim=1)
But, in most cases, you might find it easier to just use:
data_labels = [train_x, train_y]
...
train_x, train_y = data_labels[0], data_labels[1]
Thank you so much ! I will try it
Call view on a PyTorch tensor not a numpy array:
x = torch.randn(2, 3, 4, 5)
x = x.view(-1, 1, 1, 1) # works
x = np.random.randn(2, 3, 4, 5)
x = x.view(-1, 1, 1, 1) # fails
# TypeError: view() takes from 0 to 2 positional arguments but 4 were given
As @ptrblck said, if it’s a NumPy object, you’ll need to convert it into a Pytorch tensor, via torch.from_numpy():
labels[:, 0, labels.size()[1], :] = torch.from_numpy(train_y).view(-1, 1, labels.size()[1], 1)
data_labels=torch.cat([train_x, labels], dim=1)
https://pytorch.org/docs/stable/generated/torch.from_numpy.html
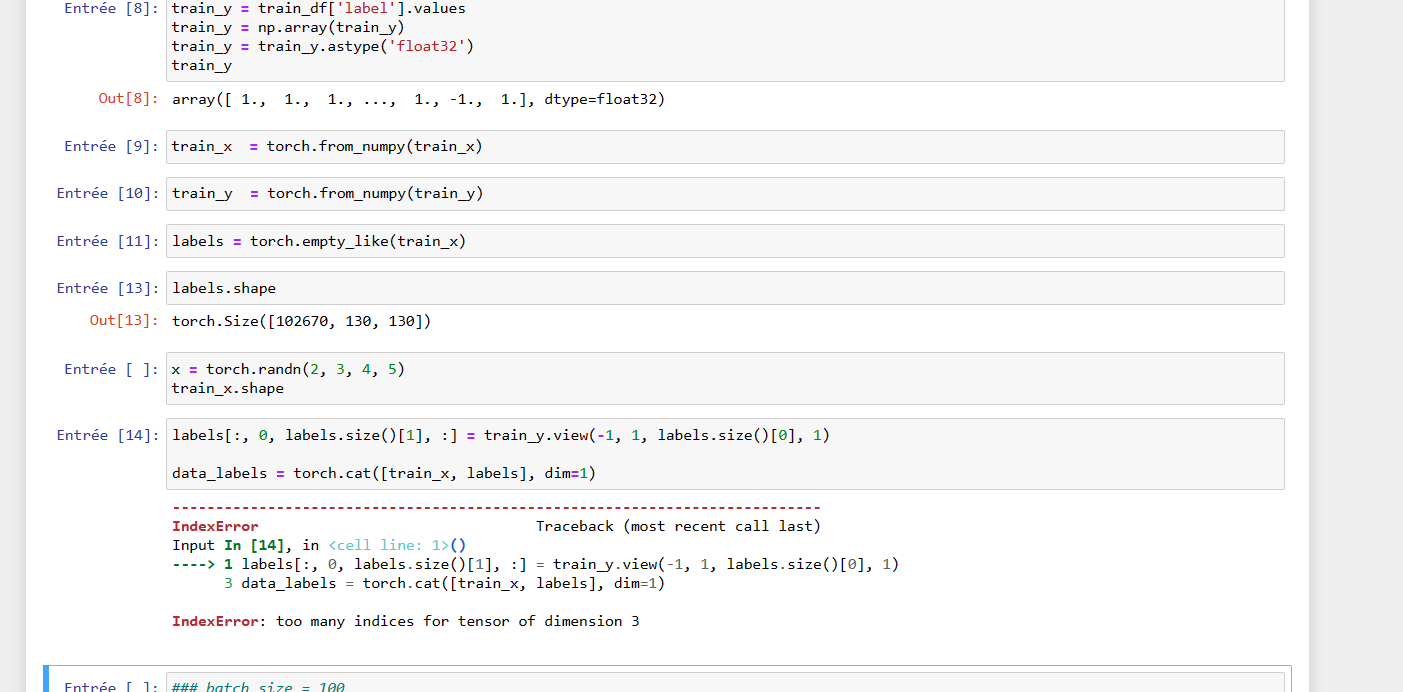
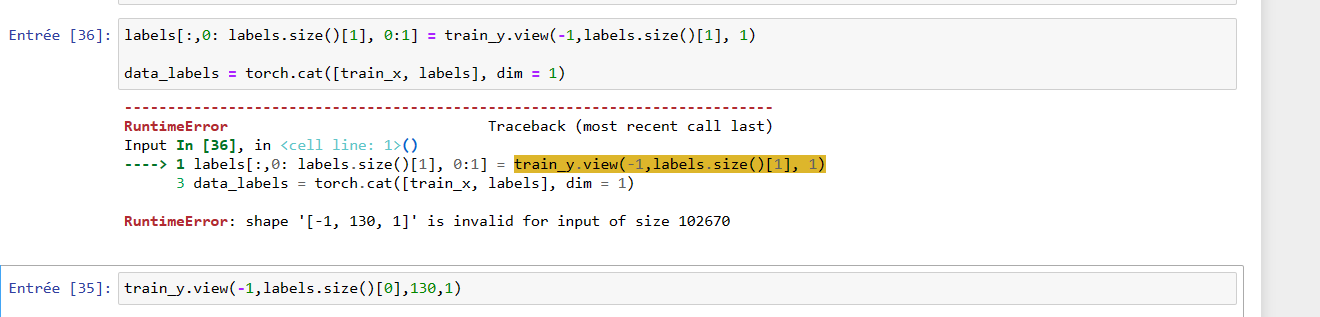
You changed train_y.view(-1,1,labels.size()[1], 1) to train_y.view(-1,1,labels.size()[0], 1). The -1 is intended to capture the batch size, as this can be variable, while the labels.size()[1] captures the number of labels per item. Change it back to dim 1 so the sizes match.
Additionally, it seems your images are removing a dim. Images should have 4 dimensions: batch size, channels, height, width.
If you are getting your images/labels from a numpy dataloader, it could be squeezing the channels dim. You’ll need that back in to pass to a model for inference, if it has convolutional layers. i.e. train_x=train_x.unsqueeze(1)
If the model is strictly linear layers, then you can resize the labels view accordingly.
As I suspected, you’re missing the channels dim. Does your model have Conv2D layers?
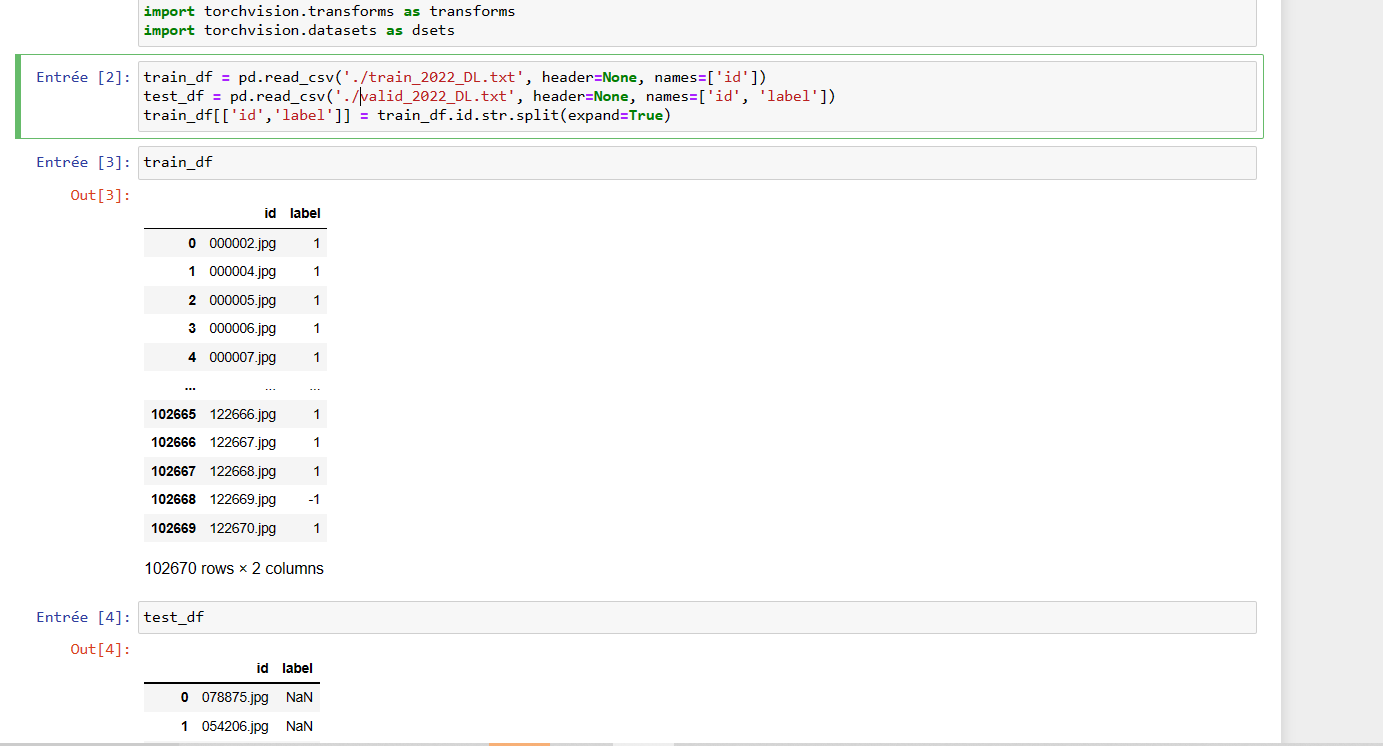
I did not train the model. In fact, for the image classification, i have a folder with human faces and two csv files : train_csv contains the name of image (ex : 0001.jpg) and the label (1 or -1). So i start to collect then into datframe.
Then just remove the 2nd dim in the .view():
labels[:,0: labels.size()[1], 0:1] = train_y.view(-1, labels.size()[1], 1)
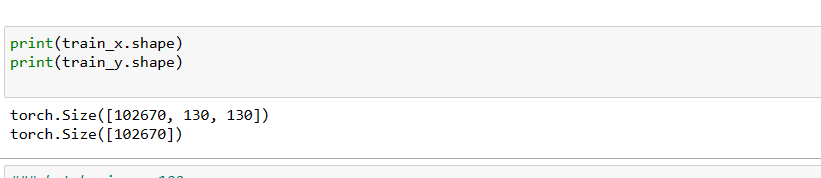
Can you print the sizes of train_x and train_y?
import torch
train_x=torch.rand(200, 130, 130)
train_y=torch.rand(200)
labels = torch.empty_like(train_x)
labels[:,:1, :1] = train_y.view(-1, 1, 1)
data_labels=torch.cat([train_x, labels], dim=1)
print(data_labels.size())