I am trying to train a ViT model modification on the ImageNet dataset from scratch.
I am using 8 Teslas V100 GPUs and it is taking enormously too long.
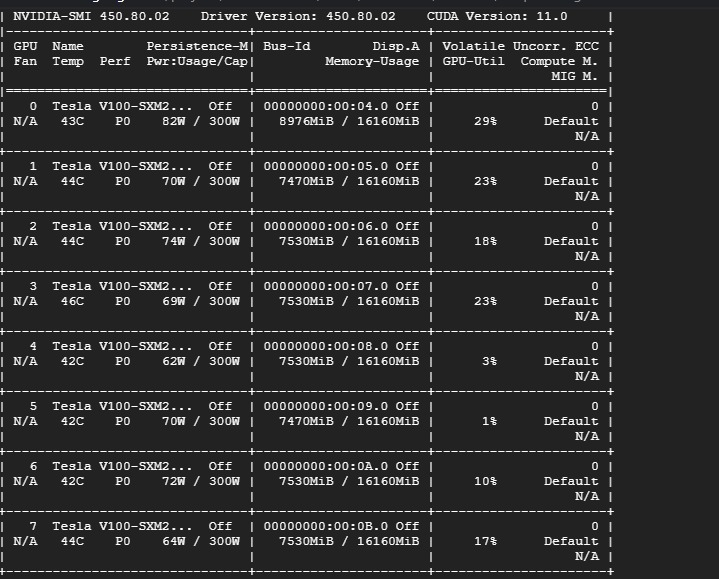
While inspecting the gpus with nvidia-smi I get:
I am using nn.DataParallel to train it. In my dataloader I am using num_workers = 8 and pin_memory=True of course.
I tried to increase the number of workers up to 16 as adviced in Guidelines for assigning num_workers to DataLoader - #4 by YossiB but it only froze the machine.
Is that normal? The estimated time per epoch is around 9 hours, I think that’s too long, specially because I intend to train it for 300 epochs
Obs: while increasing the number of workers from 0 to 8 the training time per epoch reduced from 16h to 6h, but that’s still too long.
I’ve seen some other imagenet training in 29 hours.
ResNet-50 takes 29 hours using 8 Tesla P100 GPU.
Would it be a Torch problem?
Even with 16 workers there might be a large imbalance between data loading time and GPU time. Do you have some statistics on the proportion of time spent on data in each batch (e.g., like in the classic ImageNet example here)?
So you are saying that the bottleneck is mostly loading the data (is what I suspected since for CIFAR100 it works fine).
I don’t have the statistics but I can implement them.
Thanks for the reply!
I wonder why is Distributed Data Parallel any better? I am using 8 gpus in the same machine
Anyway, any tips/ideas on how I could load imagenet faster with pytorch?
Hopefully by changing the HDD to a SSD will help.
The loading time is 5.2 sec average and the batch time is 0.8 sec =/ @eqy
You can see the short note in the docs here for why Distributed Data Parallel can be faster for multi-GPU training.
Yes, switching HDD to SSD can make a large difference, especially for “random” file I/O as loading many ImageNet images can look like random reads to storage. If you have sufficient memory, you might consider increasing the prefetch_factor in your DataLoader as well to see if increased buffering might help. However, if your HDD cannot keep up with the data loading speed, it is tricky fully utilize the GPUs.