Hi everyone!
Im trying a new approach on nodule recognition in chest x-rays with JSRT dataset where I concatenate a filtered image but i’m having problemas as my dataset is SMALL (247 images) and IMBALANCED (154 images with nodules and without).
I have something like this
original_transformation = transforms.Compose([
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
# Loading original images
original_dataset = torchvision.datasets.ImageFolder(
root=dataset_folder_path,
transform=original_transformation
)
I have a folder where the original image has the filtered one directly after (i.e: 1.jpg and 1A.jpg), so in order to concatenate I use something like this
dataset = []
for i in range(0,len(original_dataset)):
if(i%2==0):
conc_img = torch.cat((original_dataset[i][0], original_dataset[i+1][0]), 0)
conc_tuple = (conc_img , original_dataset[i][1])
dataset.append(conc_tuple)
This is a quick and dirty solution and it is kinda bad because the dataset losts all of the object methods and attributes, so in the rest of the code you will see some loops in order to get the labels, for example.
For the splitting (where I think the problem begins) I have two options which bring the same output (obviusly I comment one to run the other one). Both give me the same proportion of with/without nodule images for training and testing.
train_size = int(0.7 * len(dataset))
test_size = len(dataset) - train_size
# Random split *
train_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])
# Stritifed split *
from sklearn.model_selection import train_test_split
labels_dataset = []
for i in range(0,len(dataset)):
labels_dataset.append(dataset[i][1])
train_indices, test_indices = train_test_split(list(range(len(dataset))), test_size=test_size, stratify=labels_dataset)
train_dataset = torch.utils.data.Subset(dataset, train_indices)
test_dataset = torch.utils.data.Subset(dataset, test_indices)
For data augmentation I do something likes this (i have some doubts about it)
# First Aug
print("Augmentating...")
aug_dataset1 = []
first_transform = torchvision.transforms.RandomVerticalFlip(p=1)
for i in range(0,len(train_dataset)):
transf_img = first_transform(train_dataset[i][0])
transf_tuple = (transf_img , train_dataset[i][1])
aug_dataset1.append(transf_tuple)
# Second Aug
print("Augmentating...")
aug_dataset2 = []
second_transform = torchvision.transforms.RandomHorizontalFlip(p=0.5)
for i in range(0,len(train_dataset)):
transf_img = second_transform(train_dataset[i][0])
transf_tuple = (transf_img , train_dataset[i][1])
aug_dataset2.append(transf_tuple)
train_dataset = torch.utils.data.ConcatDataset([train_dataset,aug_dataset1])
train_dataset = torch.utils.data.ConcatDataset([train_dataset,aug_dataset2])
Finally, I wanted to balance classes so I used a code by @ptrblck for the dataloaders:
# Dataloaders
# https://discuss.pytorch.org/t/how-to-handle-imbalanced-classes/11264/2?u=ptrblck
def get_sampler(target):
class_sample_count = np.unique(target, return_counts=True)[1]
weight = 1. / class_sample_count
samples_weight = weight[target]
samples_weight = torch.from_numpy(samples_weight)
samples_weigth = samples_weight.double()
sampler = torch.utils.data.WeightedRandomSampler(samples_weight, len(samples_weight))
return sampler
train_targets = []
for i in range(0,len(train_dataset)):
train_targets.append(train_dataset[i][1])
test_targets = []
for i in range(0,len(test_dataset)):
test_targets.append(train_dataset[i][1])
train_sampler = get_sampler(train_targets)
test_sampler = get_sampler(test_targets)
b_size = 25
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=b_size,
num_workers=0,
sampler = train_sampler
#shuffle=True
)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=b_size,
num_workers=0,
sampler = test_sampler
#shuffle=True # true?
)
The network looks like this:
class Net(nn.Module):
def __init__(self, num_classes = 3):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(in_channels=2, out_channels=25, kernel_size=5, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=25, out_channels=55, kernel_size=5, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2)
self.dropout1 = nn.Dropout2d(0.4)
self.dropout2 = nn.Dropout2d(0.6)
self.fc1 = nn.Linear(in_features=50 * 50 * 55, out_features= 1882)
self.fc2 = nn.Linear(in_features=1882, out_features=num_classes)
def forward(self, x):
x = F.relu(self.pool(self.conv1(x)))
x = F.relu(self.pool(self.conv2(x)))
x = F.dropout(self.dropout1(x), training=self.training)
# Flattening
x = x.view(-1, 50 * 50 * 55)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
return x
device = "cpu"
if (torch.cuda.is_available()):
device = "cuda"
model = Net(num_classes=len(classes)).to(device)
print(model)
And the real problem is that not only the accuracy is low (about 60%), but also when I make a Confusion Matrix seems to show that the classes are not balanced at all:
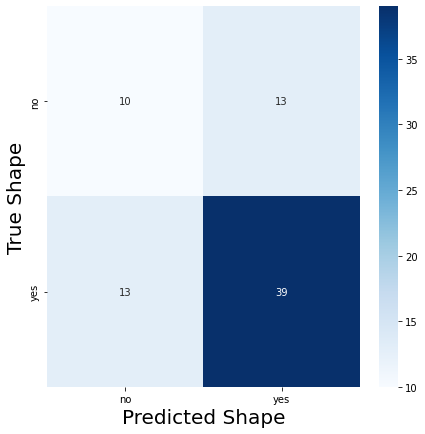
#Confusion matrix
truelabels = []
predictions = []
model.eval()
print("Getting predictions from test set…")
for data, target in test_loader:
data = data.to(device)
for label in target.data.numpy():
truelabels.append(label)
for prediction in model(data):
predictions.append(torch.argmax(prediction).item())
cm = confusion_matrix(truelabels, predictions)
tick_marks = np.arange(len(classes))
df_cm = pd.DataFrame(cm, index = classes, columns = classes)
plt.figure(figsize = (7,7))
sns.heatmap(df_cm, annot=True, cmap=plt.cm.Blues, fmt='g')
plt.xlabel("Predicted Shape", fontsize = 20)
plt.ylabel("True Shape", fontsize = 20)
plt.show()
What I’m doing wrong? Im really new not only in Pytorch but also on Python and I really want to learn how to this the right way. Really sorry for the bad english and the long post, but I already tried so many approaches that I don’t know what else I can do. Any feedback will be life saving!
Thank you very much in advance!