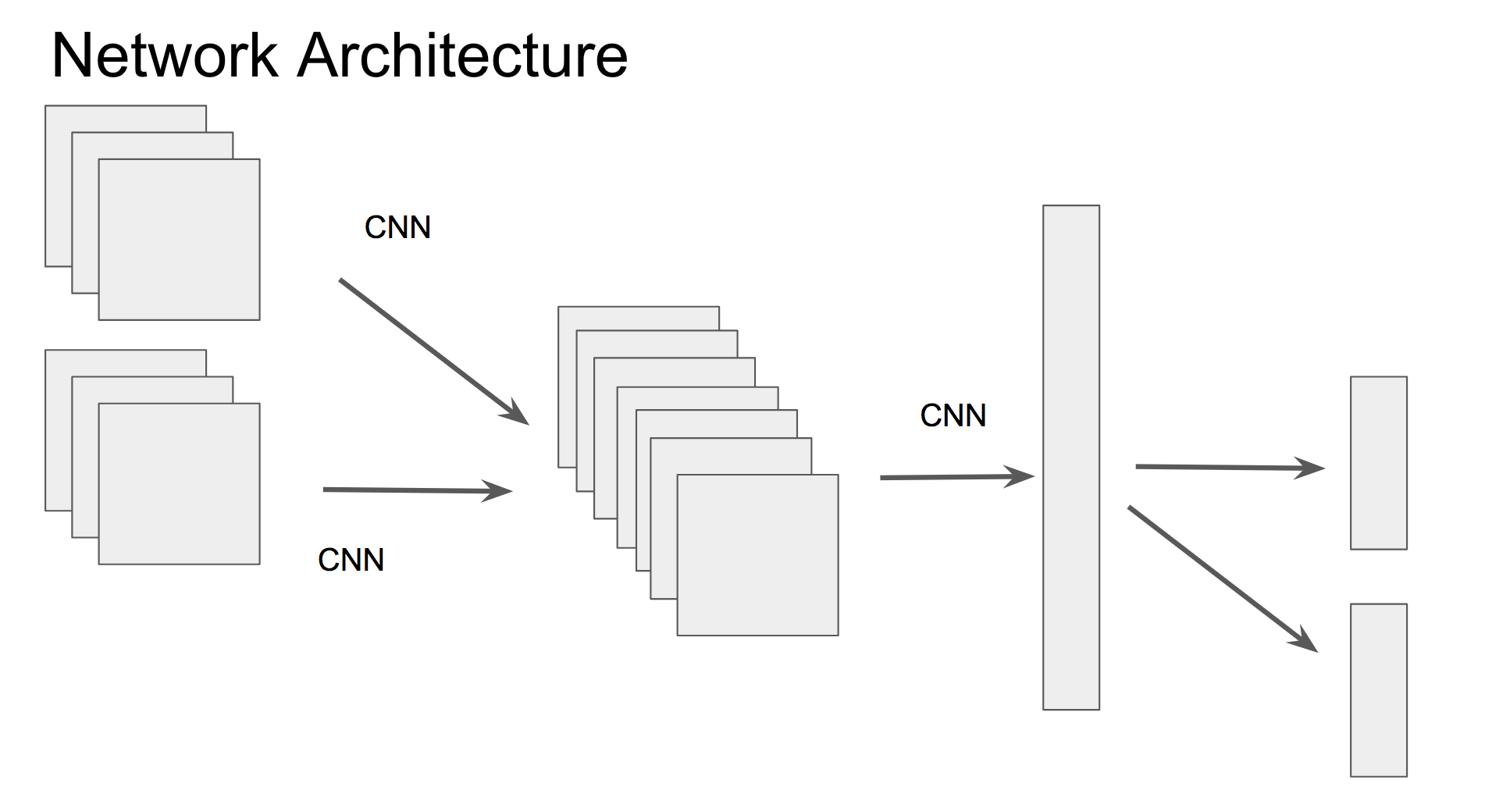
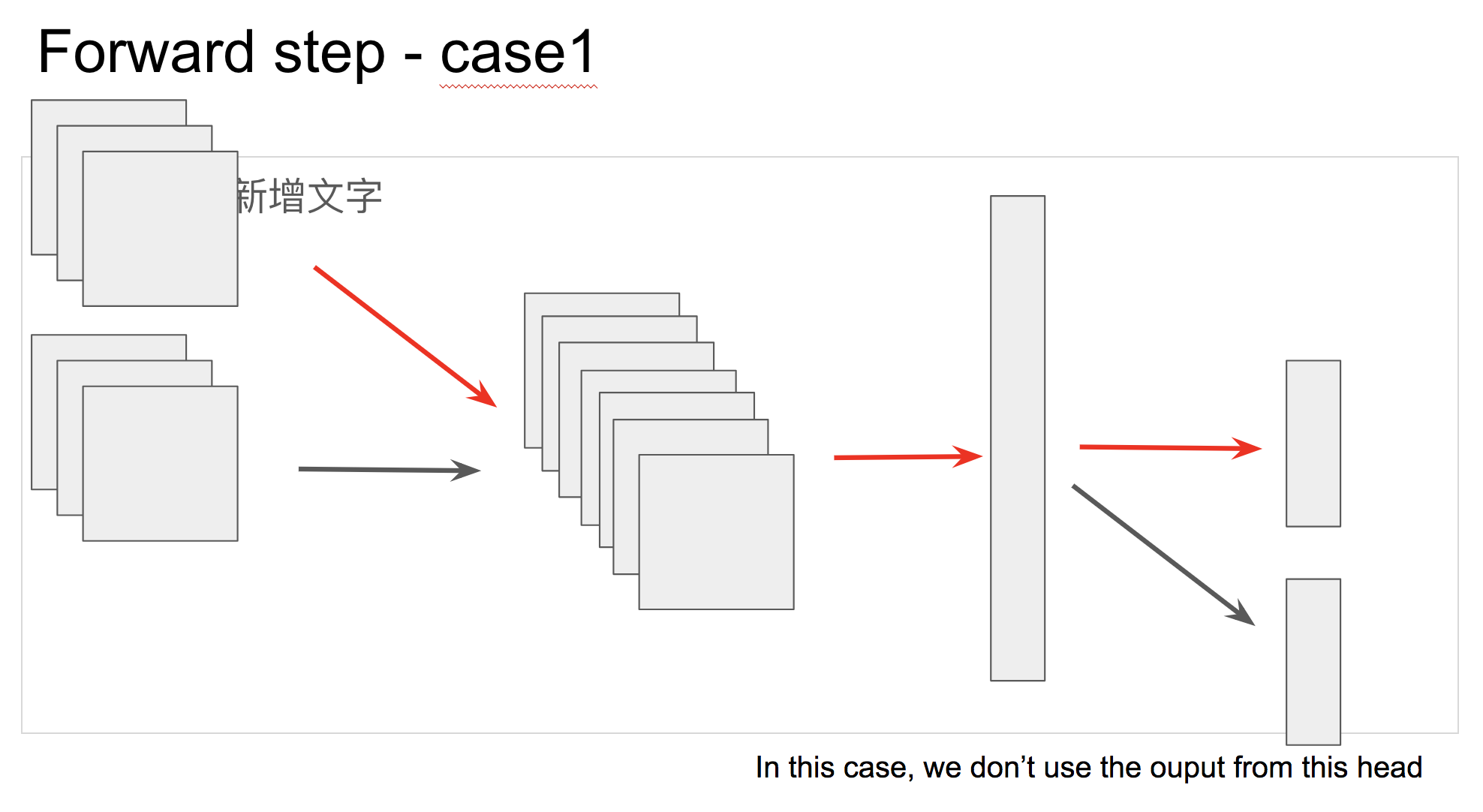
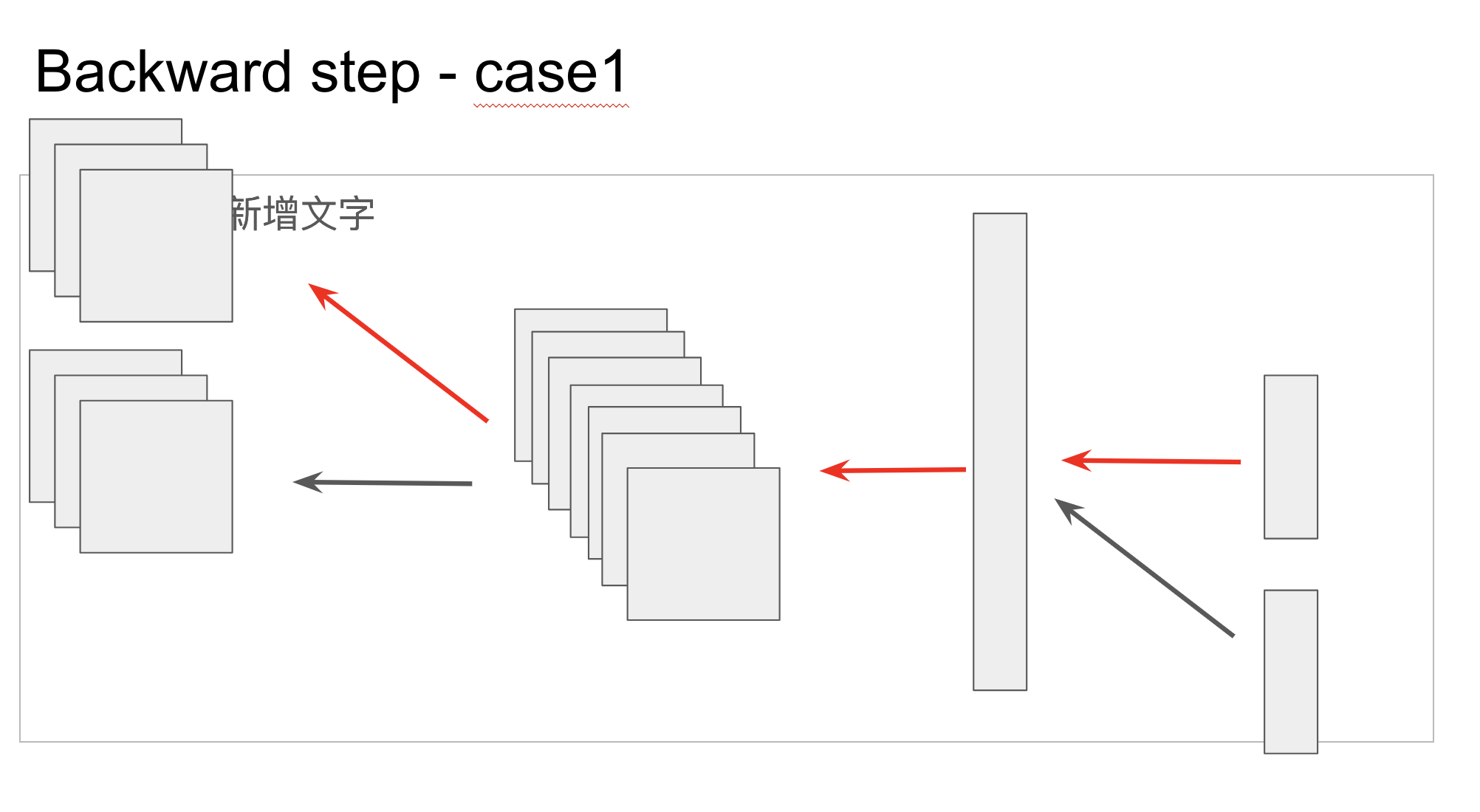
I have a special network architecture requirement which a little bit like dropouts, but drop the network modules in the specific forward path and backward path.
There are multiple input layers and multiple output layers in a single neural network. When we use this neural network, we only forward the data in 2 paths, and backward the gradients as same as it forward before.
Can we implement this kind of network by using backward hook? Any suggestion is welcomed.
If you want to know more details, please take a look at this slides: Pytorch Implementation Problem - Google Slides
The important points are that x2 is detached (so you don’t backward through conv_in_2) and the loss is just wrt out1 (so you don’t backward through fc_out_2).